


At a glance
- LLM-based models can predict the human brain’s responses to language with high accuracy. But what drives that performance is essentially unreadable: a vast collection of learned parameters, not scientific theories anyone can read.
- Generative causal testing (GCT), developed in a collaboration between Microsoft Research, the University of California, Berkeley, the University of California, San Francisco, and Columbia University, distills these brain-prediction models into short verbal explanations of what each patch of cortex responds to: phrases like “food preparation” or “location names.”
- GCT then closes the loop: an LLM writes new stories designed to activate a targeted brain area, subjects hear them in the scanner, and the region lights up only if the explanation is right.
- In experiments, GCT confirmed known selectivity, teased apart neighboring place-processing regions long thought interchangeable, and revealed tiny prefrontal “micro-regions” tuned to specific concepts like dialogue, clock times, and measurements.
The explainability problem in language neuroscience
Over the past decade, LLMs have become the most accurate tools we have for predicting how the human brain responds to language. Feed an LLM the same story a person hears in an fMRI scanner, and the model’s internal representations can predict the activity of individual patches of cortex with remarkable fidelity. But this success comes with a catch: nobody can read these models. They are millions of inscrutable parameters that can’t be directly translated into interpretations. A model that predicts brain activity tells us that a region responds to language, but not what it is actually picking up on, whether it’s food, places, numbers, or something else entirely. As black-box models spread, the gap between prediction and understanding has become one of the central problems in computational neuroscience.
Turning black boxes into testable theories
In a new paper accepted in Nature Neuroscience, Microsoft Research scientists, in collaboration with scientists at the University of California, Berkeley, University of California, San Francisco, and Columbia University, introduce a framework to overcome this explainability crisis: generative causal testing (GCT). GCT distills brain-prediction models into short, readable accounts of what each patch of cortex responds to, then tests those claims. An LLM writes new stories engineered to activate a specific brain area, subjects hear them in the scanner, and if the explanation is correct, the targeted region lights up. The result is a method that translates uninterpretable predictive models back into the currency of science: concise hypotheses that can be confirmed or refuted in a follow-up experiment. An LLM writes new stories engineered to activate a specific brain area, subjects hear them in the scanner, and if the explanation is correct, the targeted region lights up. The result is a method that translates uninterpretable predictive models back into the currency of science: concise hypotheses that can be confirmed or refuted in a follow-up experiment.
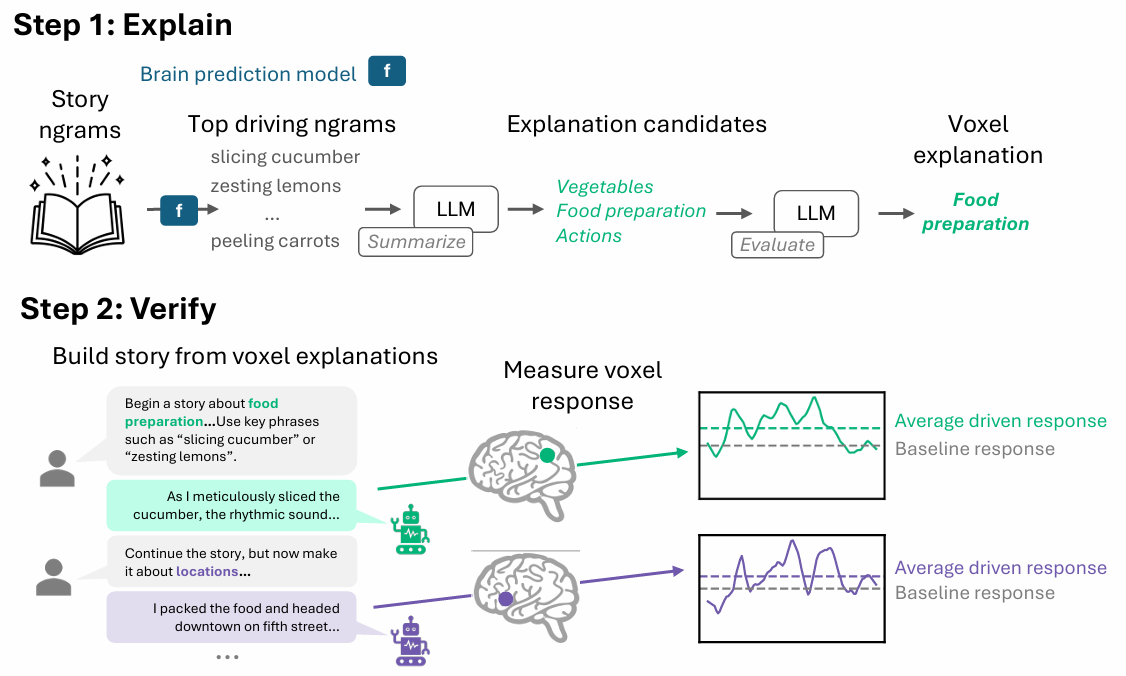
How GCT works
GCT has two steps: explanation, then verification. To generate an explanation, the method starts from a predictive model for a single voxel or region and identifies the short phrases that most strongly drive its predicted response. An LLM then summarizes those words into a concise verbal explanation, often a single phrase such as “food preparation” or “location names.”
The crucial second stage closes the loop. To build trust in the explanation, GCT uses an LLM to write new stories in which each paragraph is carefully constructed to drive a brain region according to its explanation. Three subjects returned to the scanner to read these synthetic stories. If a region’s activity to its “driving” paragraphs was significantly greater than to baseline text, the explanation passed a genuine causal test, not just a correlational one.
Across all three subjects, the core approach held up: the synthetic stories reliably drove their target regions above baseline, confirming that GCT’s short explanations capture something the cortex genuinely responds to. The explanations were also most trustworthy where the underlying brain-prediction models were strongest (the more stable the model, the more reliably its explanation could be confirmed in the scanner). With the method validated on regions whose selectivity was already known, the researchers turned GCT on harder questions.

GCT also proved sharp enough to settle long-standing ambiguities. Three neighboring regions involved in processing places have often been treated as functionally similar: the retrosplenial cortex (RSC), the parahippocampal place area (PPA), and the occipital place area (OPA). At first, stories written for one region also activated the others. But by generating differential stimuli (stories designed to switch one region on while keeping its neighbors quiet), GCT teased the three apart. For example, RSC responds more strongly to proper noun location names, like Tokyo or Connecticut, rather than general location. This is the kind of nuanced, region-specific theory that a raw predictive model cannot provide on its own.
Beyond known regions, the authors discovered new prefrontal “micro-regions.” By scanning a grid of candidate locations and keeping only the most stable ones, GCT surfaced these previously unmapped regions tuned to remarkably specific concepts: one selective for dialogue between people (words like “said” or “told”), one for mentions of clock times (“one o’clock”), and one for numeric measurements (“50 feet”). These are distinctions no one had gone looking for; they emerged because the method could propose a hypothesis and immediately test it.
PODCAST SERIES
The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
Implications and looking forward
The significance of GCT reaches well beyond neuroscience. Researchers increasingly face the same dilemma: a model that predicts beautifully but explains nothing. GCT shows that a data-driven model need not be the end of inquiry; it can be distilled into a readable, experimentally testable theory, and that theory can be checked against reality by generating new experiments on demand.
For neuroscience specifically, GCT points toward a faster, more hypothesis-rich way of mapping the cortex—one where an AI system proposes what a brain region might encode and a closed-loop experiment confirms or rejects it within a single study. The same generate-and-verify philosophy could extend to other domains where powerful predictive models have outrun our ability to understand them. The broader lesson is hopeful: the rise of black-box models in science does not necessarily mean the retreat of human-readable theory. With the right framework, the two can advance together.
Acknowledgements
This work was a collaboration across Microsoft Research, UC Berkeley (Alex Huth, Bin Yu, Sihang Guo, and Aliyah Hsu), Columbia University (RJ Antonello, co-lead), and UCSF (Shailee Jain). We also thank the study participants and the broader language-neuroscience community whose tools and datasets made this research possible.
Read the paper (opens in new tab): “Generative causal testing to bridge data-driven models and scientific theories in language neuroscience,” accepted in Nature Neuroscience and the code on Github (opens in new tab).




{kind=link}