


At a glance
- Today’s critical services and applications are often highly concurrent, using hundreds of threads. They also operate at large memory scales, frequently hundreds of gigabytes, especially when using large language models.
- mimalloc is an open-source, modern, scalable memory allocator that is a drop-in replacement for malloc and free. It is relatively small (~12K lines), with clear internal data structures, and is easy to build and integrate into other projects. It provides bounded worst-case allocation times (up to OS primitives), bounded space overhead, low internal fragmentation, and minimal contention by relying almost exclusively on atomic operations.
- mimalloc is available on GitHub (opens in new tab) and has over 12K stars.
mimalloc
At the RiSE group at Microsoft Research (MSR), we conduct fundamental research into formal methods, programming languages, and software engineering (including emerging agentic systems), with a particular focus on systems that can be provably correct, secure, and performant. The mimalloc memory allocator was initially designed in 2020 as a fast allocator for the state-of-the-art Lean (opens in new tab) and Koka (opens in new tab) programming languages developed at RiSE, both of which use novel compiler-guided reference counting (see Perceus).
The scalable design of mimalloc has also proved to work exceedingly well for large services at Microsoft. Through close cooperation with product teams, mimalloc has significantly improved the response times in services such as Bing.. Today, mimalloc is widely used in large services and applications, both within and outside Microsoft. It serves as the allocator for NoGIL CPython 3.13+, is integrated into Unreal Engine, and is used in games such as Death Stranding.
The project is open source on GitHub, with over 12K stars. Its Rust wrapper alone sees over 100K downloads per day.
mimalloc is effective across a wide range of scenarios; from small-scale applications like Koka or Lean, to large services with memory footprints exceeding 500 GiB and hundreds of threads.
Despite this range, the codebase is still compact, at around 12K lines of C. Reflecting its research origins, mimalloc emphasizes clear internal data structures with strong invariants, making it easier to understand and reason about than many industry allocators. As Fred Brooks already remarked in his famous book The Mythical Man-Month: “Show me your flowchart and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won’t need your flowchart; it’ll be obvious.”
As a result, mimalloc has been ported to many platforms—Windows, macOS, Linux, FreeBSD, NetBSD, DragonFly, and various consoles—, and is easy to build and integrate into other projects. For example, the clear data structures enabled Sam Gross and others to adopt mimalloc as the concurrent allocator for NoGIL CPython. The design also makes itrelatively straightforward to implement cyclic garbage collection on top of this.
The Fast Path
As with other scalable allocators (such as tcmalloc and jemalloc), a core design principle of mimalloc is that each thread maintains its own thread-local heap, which we call a “theap”. Each theap owns a set of mimalloc “pages,” which are usually 64 KiB. Each mimalloc page contains blocks of a fixed size, organized into size classes to reduce internal fragmentation. By giving each thread its own theap and set of mimalloc pages, memory allocation and deallocation typically proceed without synchronization. Atomic operations are only required when a thread frees a block allocated by another thread.
Moreover, in practice, most allocations are quite small, often less than 1 KiB. For such small allocations, mimalloc provides a fast path where the main allocation function looks like:
void* mi_malloc( size_t size )
{
mi_theap_t* const theap = mi_get_thread_local_theap();
if (size > MI_MAX_SMALL_SIZE) return mi_malloc_generic(theap,size); // slow generic path
const size_t index = (size + sizeof(void*))/sizeof(void*); // round size
mi_page_t* const page = theap->small_pages[index];
mi_block_t* const block = page->free; // head of free list
if (block == NULL) return mi_malloc_generic(theap,size); // slow generic path
page->free = block->next; // pop free list
page->used++;
return block;
}By using thread-local theaps, we need no atomic operations or thread synchronization. We also try to minimize the number of branches. In particular, the thread-local theap is never NULL, and we initialize it with a special empty theap with all empty pages. This way, we do not need a separate check if the theap is NULL. Similarly, the pointers in the small_pages array are never NULL, and we use again special empty pages (with page->free==NULL) to avoid a separate check. Finally, pages are initialized with a free listrather than a separate bump pointer, avoiding special cases and enabling allocation by simply popping blocks from the free list. On x64, this code now translates into few instructions with just two uncommon branches:
mi_malloc:
movq %rdi, %rsi ; rsi = size
movq _mi_theap_default@GOTTPOFF(%rip), %rax
movq %fs:(%rax), %rdi ; rdi = thread local theap
cmpq $1024, %rsi ; size > MI_MAX_SMALL_SIZE?
ja .LBB0_generic
leaq 7(%rsi), %rax ; round to sizeof(void*)
andq $-8, %rax
movq 232(%rdi,%rax), %rcx ; rcx = heap->small_pages[index]
movq 8(%rcx), %rax ; block = rax = page->free
testq %rax, %rax ; block == NULL?
je .LBB0_generic
movq (%rax), %rdx ; page->free = block->next
movq %rdx, 8(%rcx)
incw 16(%rcx) ; page->used++
retq
.LBB0_generic:
jmp _mi_malloc_generic@PLT ; tailcall
Similarly, mimalloc provides a fast path for freeing blocks. In practice, most blocks are freed by the same thread that allocated the block. We can optimize that case by checking whether the current thread ID matches the thread ID stored in the corresponding mimalloc page. If so, we can just push our block on the page’s free list without requiring atomic operations or locks:
void mi_free(void* p)
{
mi_page_t* const page = mi_ptr_page(p); // get the page meta-data that contains p
if (page==NULL) return;
if (mi_thread_id() == page->thread_id) { // do we own this page?
mi_block_t* const block = (mi_block_t*)p;
block->next = page->local_free; // push on the `local_free` list
page->local_free = block;
if (--page->used == 0) mi_page_free(page); // is the entire page free?
}
else {
mi_free_cross_thread(page, p); // free in a page owned by another thread
}
} The mi_ptr_page function in the latest mimalloc v3 retrieves page metadata using an on-demand allocated map of the entire memory. In earlier versions this was faster using alignment tricks. However, in practice, invalid pointers are often passed to mi_free when overriding free globally.
Using a separate map enables such cases to be detected efficiently and return NULL when the pointer is invalid. In particular, mi_ptr_page(NULL) == NULL, which avoids an extra branch by testing only if the page is NULL. Additionally, used count is used to efficiently detect when all blocks in a page have been freed.
When a block is freed across threads, we enter the mi_free_cross_thread function—the first path that requires atomic operations:
void mi_free_cross_thread(mi_page_t* page, mi_block_t* block)
{
mi_block_t* tfree = mi_atomic_load(&page->thread_free); // head of the thread free list
do {
block->next = tfree; // push our block in front
} while (!mi_atomic_compare_and_swap(&page->thread_free, &tfree /*expect*/, block /*new*/))
}The block can be freed by pushing it onto the thread-free list of the page. Since this is multi-threaded, it requiresan atomic compare-and-swap operation to push the block atomically. Still, on modern hardware such operations are efficient when uncontended, as their operation is integrated with the cache coherence protocol (MOESI).
Spotlight: Microsoft research newsletter
Microsoft Research Newsletter
Free list mayhem
There are three free lists per page: the free list for allocations, the local_free list for freed blocks, and the thread_free (atomic) list for blocks that were freed across threads. This guarantees that after a fixed number of allocations, the free list is exhausted, ensuring we occasionally take the slower generic allocation path. This is also used to clean up the free lists by moving thread-local and local free lists back to the main free list. (Note: Actual implementation requires more care to handle cases where the owning thread never allocates again or is blocked for a long time).
Thus, mimalloc has three free lists per (64 KiB) mimalloc page, and effectively that means that a program can easily have thousands of free lists. This is essential to the scalability and cache locality of mimalloc.

For this design, we took inspiration from randomized algorithms. For example, to balance a binary tree we can use smart strategies based on weight or depth, and perform specific rotations to keep it balanced. Such algorithms are usually quite complicated. However, we can also simplify the process and randomly decide on splits during insertion, and by sheer chance, we also end up with trees that are balanced enough.
Similarly, many multi-threaded allocators rely on sophisticated concurrent data structures to synchronize access to shared free lists. In contrast, mimalloc uses a per-page thread-free list, where any thread can push a block using a simple atomic compare-and-swap.
Because there are thousands of such lists, the probability that multiple threads concurrently free blocks to the same page is low. As a result, most push operations are uncontended atomic updates.
By organizing these lists per 64 KiB mimalloc page, cache locality is improved, as allocation tends to stay within the same page until it is full, regardless of freed objects in other pages.
In contrast, consider a design with a single free list per thread or process. When allocating a new structure while freeing objects of the same size—a common pattern in workloads such as tree transformations—allocation may reuse recently freed blocks scattered throughout memory, leading to reduced locality.
Sharing between threads
There is a fundamental tension between scalability and efficient memory sharing between threads. To scale optimally, we would give each thread exclusive ownership to its own pages to minimize any thread synchronization. On the other hand, that may lead to wasted memory: suppose a thread has large quantities of free blocks and another thread needs to allocate blocks of that size –without being able to share or steal those pages, we need to allocate fresh memory instead. In the other extreme, we could share all pages between all threads with a single lock: now memory use is optimal, but we no longer scale. The following benchmark results illustrate this tension:
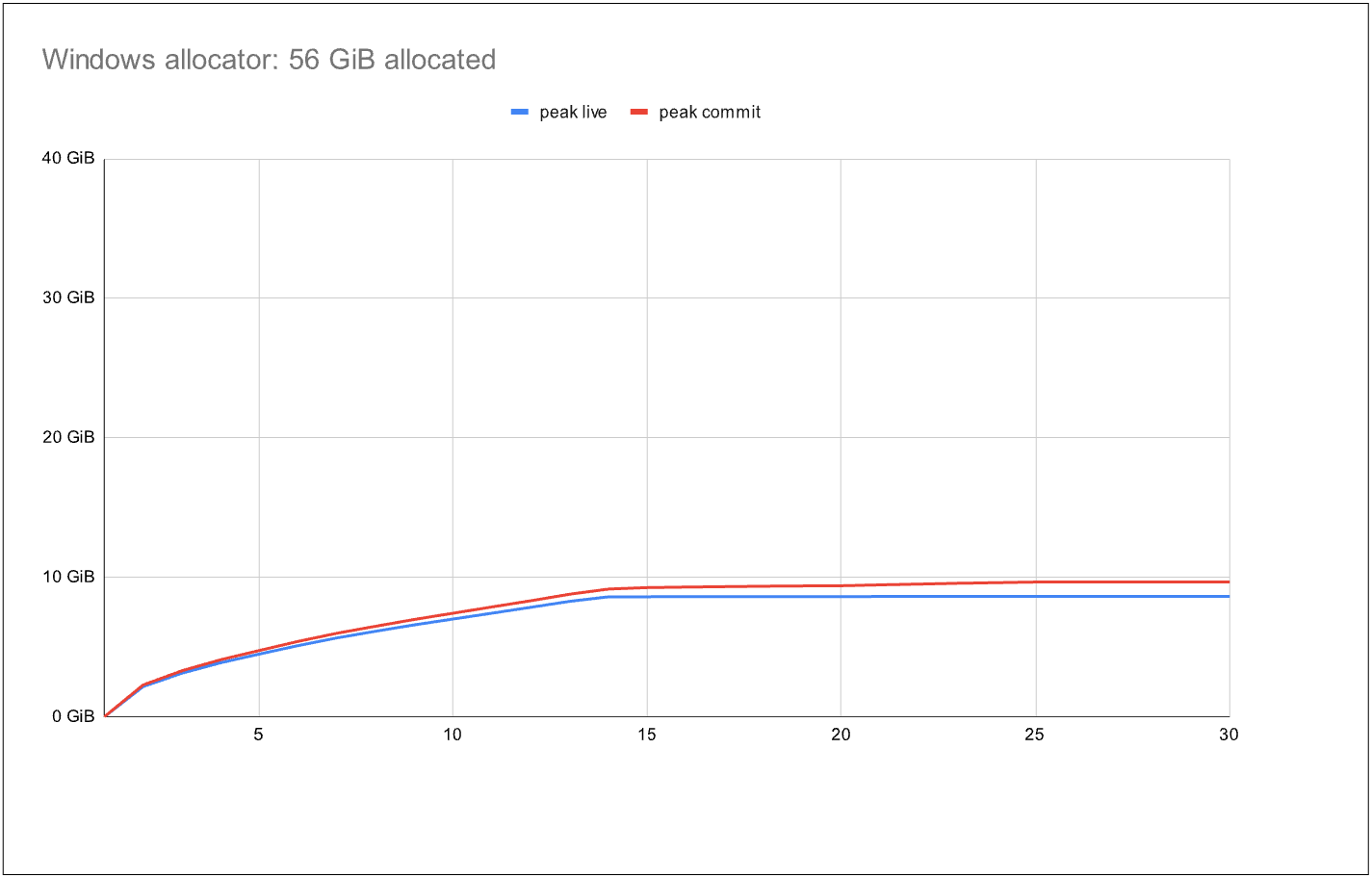
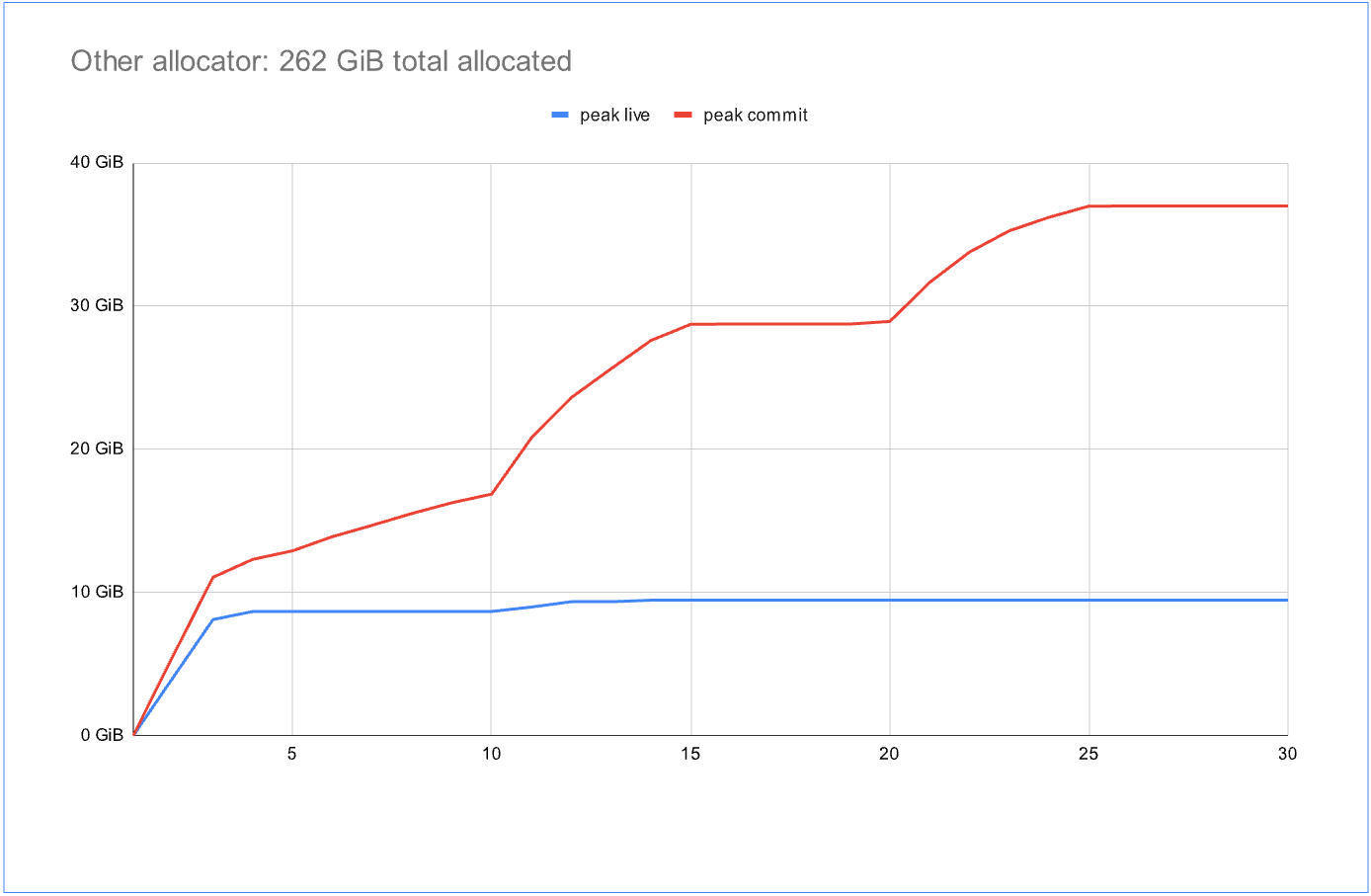
The benchmark runs many tasks for a fixed amount of time using the Windows thread pool with about 800 active threads. The tasks alternate between allocation, deallocation, and brief blocking periods, simulating typical service workloads. In the graphs, the blue line represents the total live data, while the red line represents total committed memory by the allocator. The ideal situation is to have the red line as close as possible to the blue line. This is almost the case for the first graph, which uses the standard system allocator: at the end there is just 1.1x more committed than live data – an excellent result! However, over the benchmark duration, it allocated a total of only 56 GiB data.
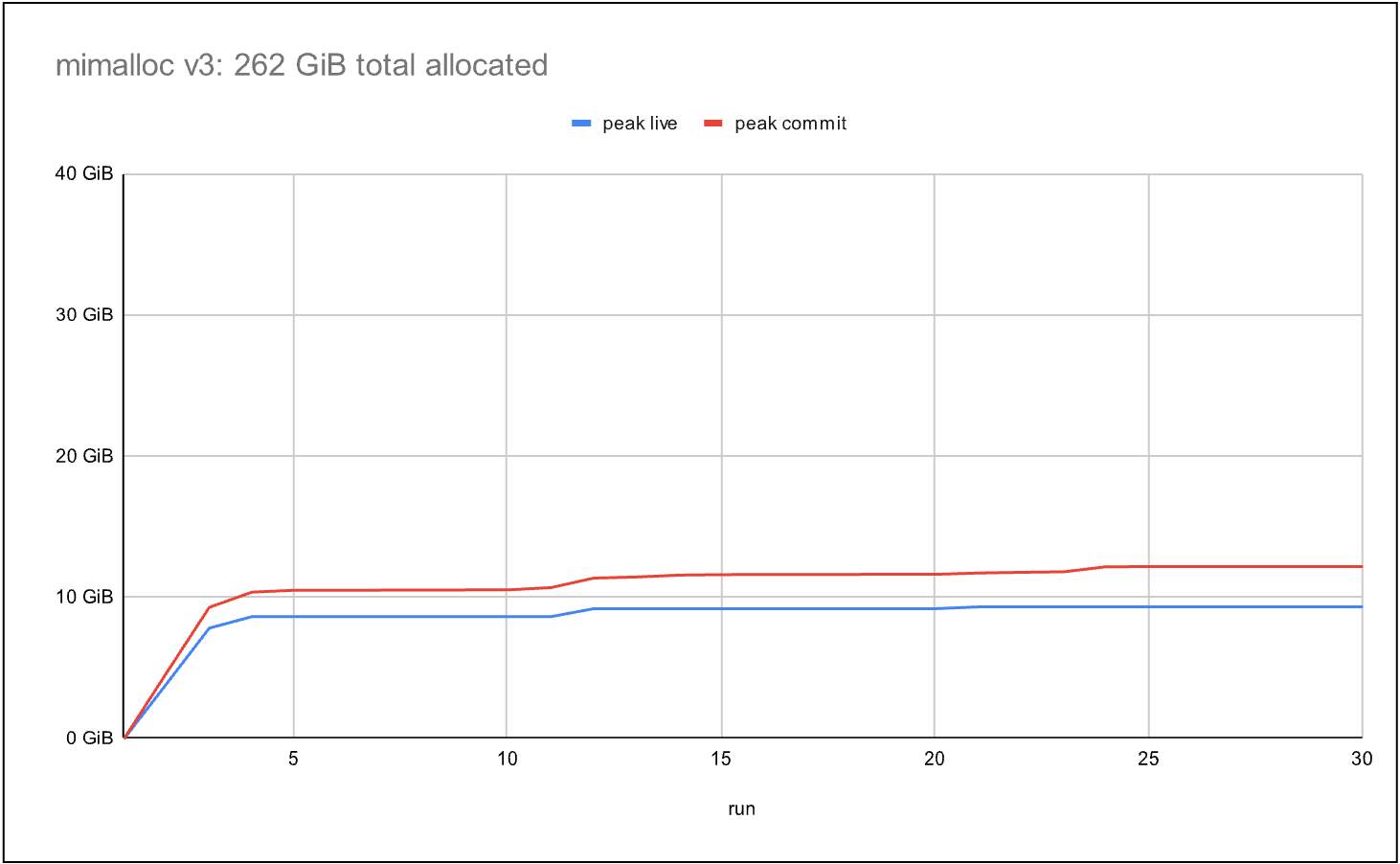
Contrast that with another highly concurrent allocator in the second graph, which was able to allocate 262 GiB over the benchmark duration—almost 4x as much. However, it also committed 4x more memory than the live data. In real workloads with larger memory footprints, such a ratio can quickly become unacceptable. Here we see that the standard allocator didn’t scale as well, but showed better cross-thread memory sharing.
The final graph shows the most recent mimalloc allocator. Like the second allocator, it allocates 262 GiB over the benchmark duration, while reducing committed memory to 1.3xthe live data, which achieves scalability and efficient memory sharing between threads. Similar to work-stealing in modern thread pool implementations, mimalloc uses a “page stealing” technique, allowing threads to take ownership of pages without expensive cross-thread synchronization.
These improvements were made in close collaboration with the Azure Cosmos DB team at Microsoft. A precise description is beyond the scope of this blog, but we will publish a technical report soon—stay tuned.



{kind=link}