

Business leaders across industries rely on operational dashboards as the shared source of truth that their teams execute against daily. But dashboards are built to answer known questions. When teams need to explore further, ad-hoc, multi-dimensional, or unforeseen questions, they hit a bottleneck. They wait hours or days for BI teams to build new views or update reports. The Dataset Q&A feature bridges that gap. You can ask questions in natural language, get accurate answers in seconds, with no new dashboards to build, and no queue to wait in. Just an interactive conversation with your existing datasets, without disrupting the dashboards your teams already depend on.
The challenge
AWS customers expect fast, informed support when they’re evaluating new technologies, troubleshooting production issues, or planning cloud transformations. To deliver that experience at scale, AWS technical field teams need immediate answers to complex operational questions: Where is customer demand increasing? Which teams have the right expertise to respond? Are customer engagements being resolved quickly enough? And where are emerging gaps that could impact customer outcomes?
The AWS Technical Field Communities (TFC) program supports hundreds of thousands of these customer engagements annually across dozens of specialized technology domains. For program leaders and field teams, understanding the pulse of these engagements isn’t just about tracking metrics; it’s about making sure that we have the right skills in the right places at the right time to help our customers succeed. Yet, as the scale of these engagements grew, so did the complexity of the questions our leaders needed to answer. Traditional, static dashboards began to struggle under the weight of sophisticated, multi-dimensional inquiries. Stakeholders found themselves navigating a maze of different systems, manually cross-referencing datasets just to get a clear picture of how to better serve the customer. Getting to the “why” behind the data isn’t always a hard technical problem, it’s a workflow problem. A leader’s question becomes an interruption for a BI engineer, who pauses planned work, runs the aggregation, and returns an answer that inevitably spawns the next question. The real time lost isn’t in the query. It’s in the handoff between the person with the question and the person with the tools to answer it. Leaders were asking complex, real-time questions that crossed organizational and technical boundaries.
While the data existed, it was often “trapped” behind rigid visualizations that couldn’t anticipate every nuance of a program leader’s needs. Furthermore, the presence of personally identifiable information (PII) meant that certain qualitative details, the very context that makes data actionable, remained restricted and difficult to surface safely.
Introducing TARA: The future of conversational analytics
To bridge this gap, AWS developed TARA (Technical Analysis Research Agent). While TARA has been built for the internal analytics needs of AWS, the Dataset Q&A capabilities that we used are available to Quick customers facing similar challenges. Built by the Specialist Data Lens (SDL) team, TARA is an AI-powered analytics assistant that uses the custom chat agent capabilities of Quick. TARA serves as a unified conversational interface that you can use to explore multiple integrated datasets, live system APIs, and specialized research agents through natural language. By using MCP to securely connect structured datasets with external systems and domain-specific research agents, TARA bridges the gap between quantitative metrics and qualitative context. This allows leaders to tie quantitative metrics to the ground truth of what’s happening in the field, enriching analytical insights with real-time operational context while making sure sensitive PII remains protected.
We evolved TARA’s conversational analytics capabilities by adopting the Dataset Q&A feature as the foundation for semantic query generation and insight delivery. This post explores that journey and the impact of business users interacting with data more naturally. By embedding semantic definitions directly into the dataset and grounding SQL generation in the business meaning of the data, Dataset Q&A significantly improved the quality and reliability of insights. This enhancement delivered more than a 48 % improvement in response accuracy, reduced query failures to near zero, and shortened analysis time from hours to minutes.
Introducing Dataset Q&A
In Q1 2026, the SDL team became early adopters of the Dataset Q&A feature, unlocking the ability to ask natural language questions and receive answers directly from data, without needing to build topics or dashboards. At its core, Dataset Q&A translates natural language into SQL at query time, grounded in semantic definitions that live on the dataset itself rather than in a separately maintained Topic. This means the business meaning of your data, including field descriptions, synonyms, and dataset instructions, is defined once and reused everywhere.For the SDL team, this was a significant breakthrough. Program leaders could finally ask the questions that actually mattered, without waiting for BI teams to update business term definitions or configure new field mappings. That meant deep operational questions, advanced trend analysis, and open-ended exploration , all answered accurately and on demand.
The architectural difference made this possible. Instead of routing queries through preconfigured field definitions and business rules, Dataset Q&A dynamically interprets user intent, identifies the relevant datasets, and generates improved SQL at query time, giving the system the flexibility to handle complex, multidimensional analysis that the previous Topic based model couldn’t.
The SDL team participated in early testing, and the results were immediate. To measure query accuracy, we conducted structured ground truth testing by comparing TARA’s generated answers against manually validated SQL queries and analyst reviewed expected outputs across a representative set of real-world scenarios. Three improvements stood out:
- Accuracy: Query accuracy improved by about 48% on ground truth benchmarks.
- Reliability: Complex analytical questions that previously failed began executing successfully, reducing query failures to near zero.
- Speed: Response times improved from minutes (about 2–3 min) to seconds (about 10 sec), an over 90% reduction, enabling near-instant data exploration.
Together, these gains transformed TARA from a helpful reporting assistant into a reliable decision support tool for AWS program leaders.
Getting started
Before implementing direct dataset Q&A in your environment, make sure that you have:
- An AWS account. For setup instructions, see Getting Started with AWS.
- Amazon Quick Enterprise Edition enabled in your account with at least one Enterprise user and Professional user. For details, see Amazon Quick Sight editions and pricing.
- Familiarity with Amazon Quick Sight concepts such as datasets and the chat interface. See the Amazon Quick Sight documentation to get started.
Technical deep dive: The TARA architecture
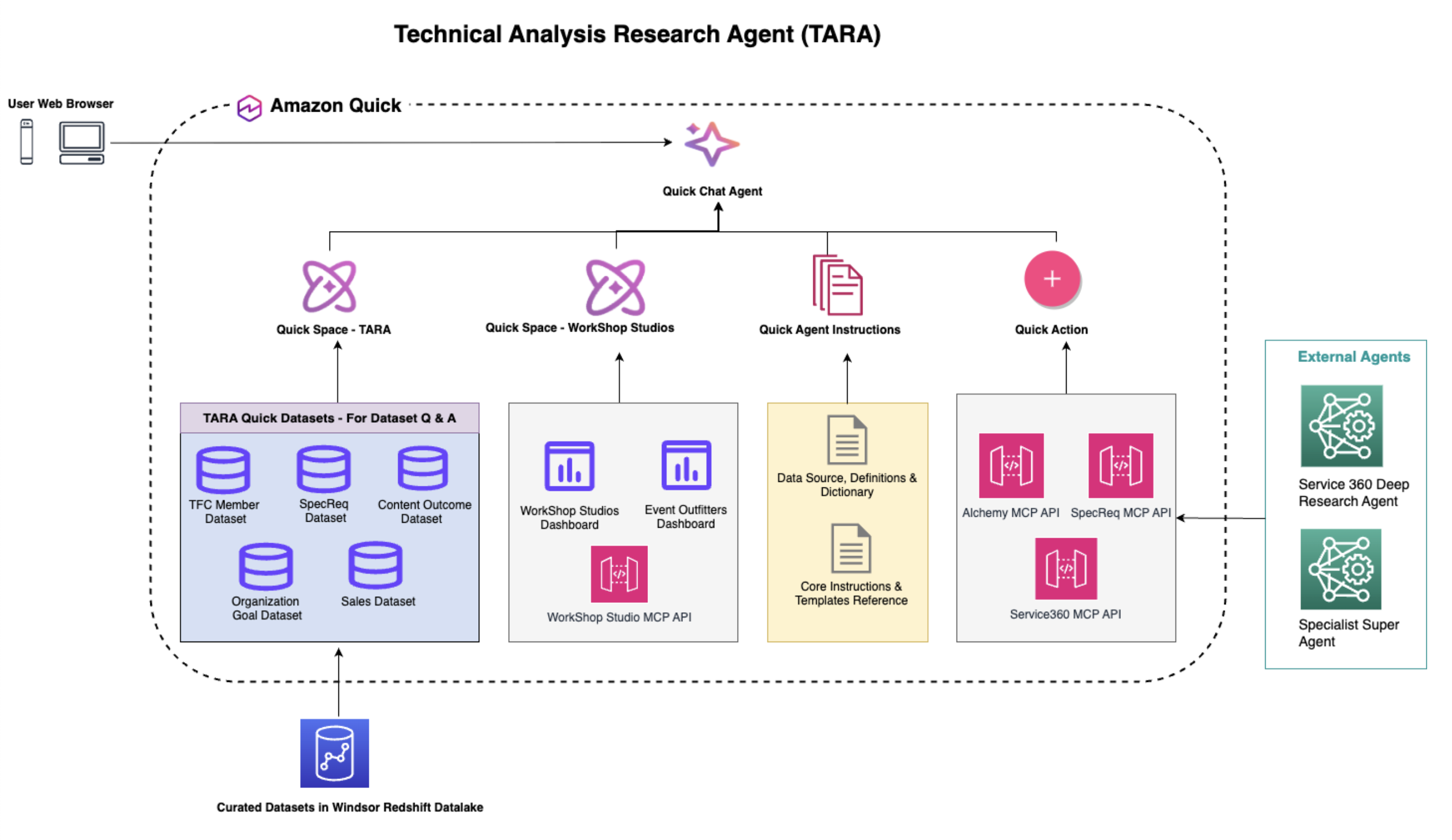
System architecture and connected intelligence
TARA’s architecture is built on top of Amazon Quick and is designed to unify structured analytics, operational systems, and institutional knowledge into a single conversational interface. At the center of the experience is the Amazon Quick Chat Agent, which serves as both the user entry point and the orchestration hub for requests. Through a straightforward natural language interface, AWS leaders can access curated business datasets, live system APIs, and specialized research agents without switching tools.
The architecture follows four tightly integrated layers:
1. User Access and Orchestration Layer
Users interact with TARA through a web browser using the Amazon Quick Chat Agent. This chat interface acts as the primary client for conversational analytics, securely authenticating users through their AWS accounts and routing requests across the broader TARA environment. It acts as an intelligent orchestration layer that determines whether a query should be answered using structured dashboards, governed datasets, operational APIs, or external agents.
2. Dataset Q&A and Workspace Integration Layer
TARA’s core analytics foundation is powered by curated datasets hosted in the Windsor Amazon Redshift data lake and surfaced through Amazon Quick Spaces, which organize data into secure logical domains for discovery and reuse across teams. A key capability of TARA is its use of Amazon Quick’s Dataset Q&A feature, which allows users to query operational metrics, member performance, specialist requests, content outcomes, organizational goals, and sales insights using natural language. By connecting datasets directly to Quick Spaces attached to TARA, the system makes trusted insights instantly accessible without requiring users to understand schemas, dashboards, or query logic. The primary TARA Space hosts foundational business datasets for operational and performance analysis, while a separate Workshop Studio Space provides access to workshop and event delivery data through dashboard and MCP integration. This cross-space design demonstrates how Amazon Quick enables secure federation of data assets across organizational boundaries while preserving ownership and governance.
3. Semantic Intelligence Through Custom Agent Instructions
A key differentiator in TARA’s architecture is its semantic intelligence layer, powered by carefully designed custom agent instructions. This layer defines business logic, domain terminology, metric interpretation rules, and business semantics so that responses are contextually accurate and consistent. Rather than relying only on raw schema or table names, TARA uses instruction-driven reasoning to interpret user intent in business terms. For example:
- “Active members” are interpreted based on status flags rather than membership tier
- Specialist request resolution rates are calculated using only completed engagements, excluding cancelled requests
- “Current month” defaults to the most recent month with complete data, not the current calendar month
These instruction sets function as a semantic translation layer between business language and underlying data structures. This is critical for building trust in executive-facing insights and facilitating consistent, reliable answers across users.
4. Connected Systems and Action Layer
Beyond structured analytics, TARA extends into operational workflows and deep research through Amazon Quick Actions and MCP integrations. This action layer allows TARA to connect directly to systems AWS teams already use, making it more than a reporting assistant.
Current integrations include:
- Alchemy: supports priority customer use case discovery and curates AWS and partner solution assets, technical validation resources, and sales plays.
- SpecReq: supports specialist request intake, routing, tracking, and fulfillment across technical support engagements.
- Service 360 Deep Research Agent: performs deep analysis of product feature requests, specialist request trends, and customer pain points to uncover insights beyond standard dashboards.
TARA is also designed for future extensibility, with planned integrations including:
- Specialist Super Agent: a framework of AI agents delivering on-demand technical expertise across more than 30 technology domains.
- InstructAI: a workflow automation and business intelligence service for revenue, pipeline, and performance insights.
This layered architecture makes TARA more than a traditional analytics assistant. It’s a connected intelligence system that combines governed data, native conversational analytics, semantic reasoning, live operational context, and specialized AI capabilities to help AWS leaders make faster, better-informed decisions.
Solution overview
TARA integrates multiple structured datasets into a unified conversational analytics experience through the direct Dataset Q&A capability. The implementation consists of four stages:
Stage 1: Custom chat agent configuration
TARA is configured as a custom Amazon Quick chat agent with tailored instructions that define business semantics, domain expertise, and response behavior. As described in the previous architecture section, these instructions make sure that user questions are interpreted consistently in the context of SDL business logic. The Spaces and Actions configured in the following stages are then linked to this agent.
Stage 2: Dataset Preparation and Integration
The core analytics datasets are connected directly to an Amazon Quick Space. To set this up, navigate to the Spaces section in the Amazon Quick side panel and create a new Space. After naming the Space and defining its purpose, add the relevant Quick Sight datasets from the available data assets. In TARA’s case, this includes seven datasets spanning membership, competency tracking, specialist request resolution and performance metrics, domain level reporting, and individual contribution details. These datasets retain their native schema, column definitions, and data types, with no separate semantic modeling required. Because datasets are refreshed on their existing schedules, TARA consistently queries current data.
Stage 3: Action integration using MCP
To extend TARA beyond structured datasets, external systems are connected through Amazon Quick Actions. These Actions integrate with MCP servers from different systems, allowing TARA to retrieve live operational data and contextual information at query time. To configure this, create a new Action in the Integrations section of Amazon Quick, connect it to the target MCP server, and link the Action to the TARA chat agent.
Stage 4: Natural Language Query Processing
When a user submits a question, the Dataset Q&A engine interprets the natural language intent and generates optimized SQL queries directly against the connected datasets. The engine dynamically identifies relevant datasets, determines joins and filter conditions, applies aggregations, and constructs the query at runtime. For contextual questions that require operational system data, TARA automatically routes requests to the appropriate MCP Action. For example, a question about specialist request resolution rates generates SQL against structured datasets, while a request for recent customer interaction details is routed to the relevant MCP integration for live context retrieval.
TARA in action:
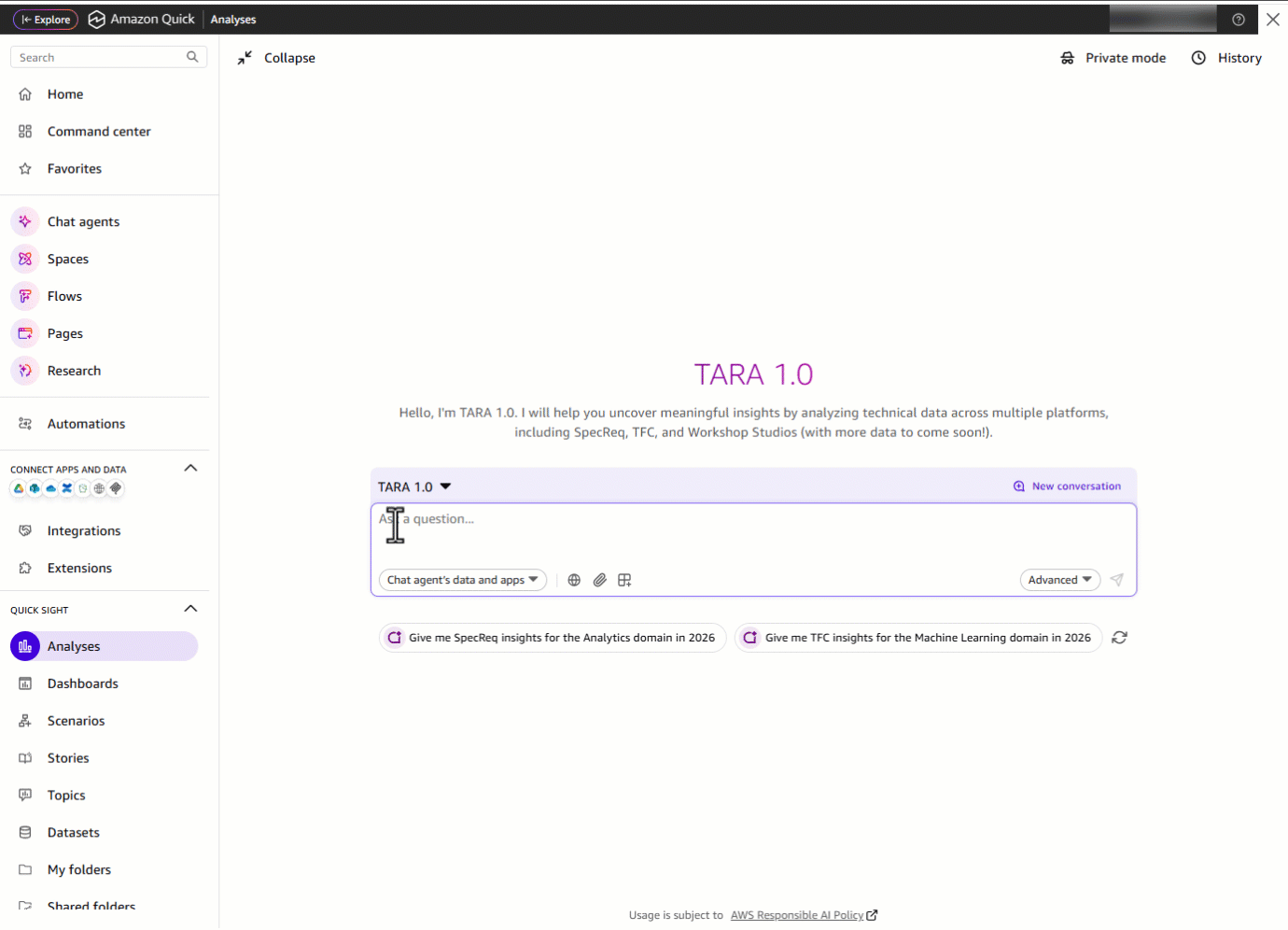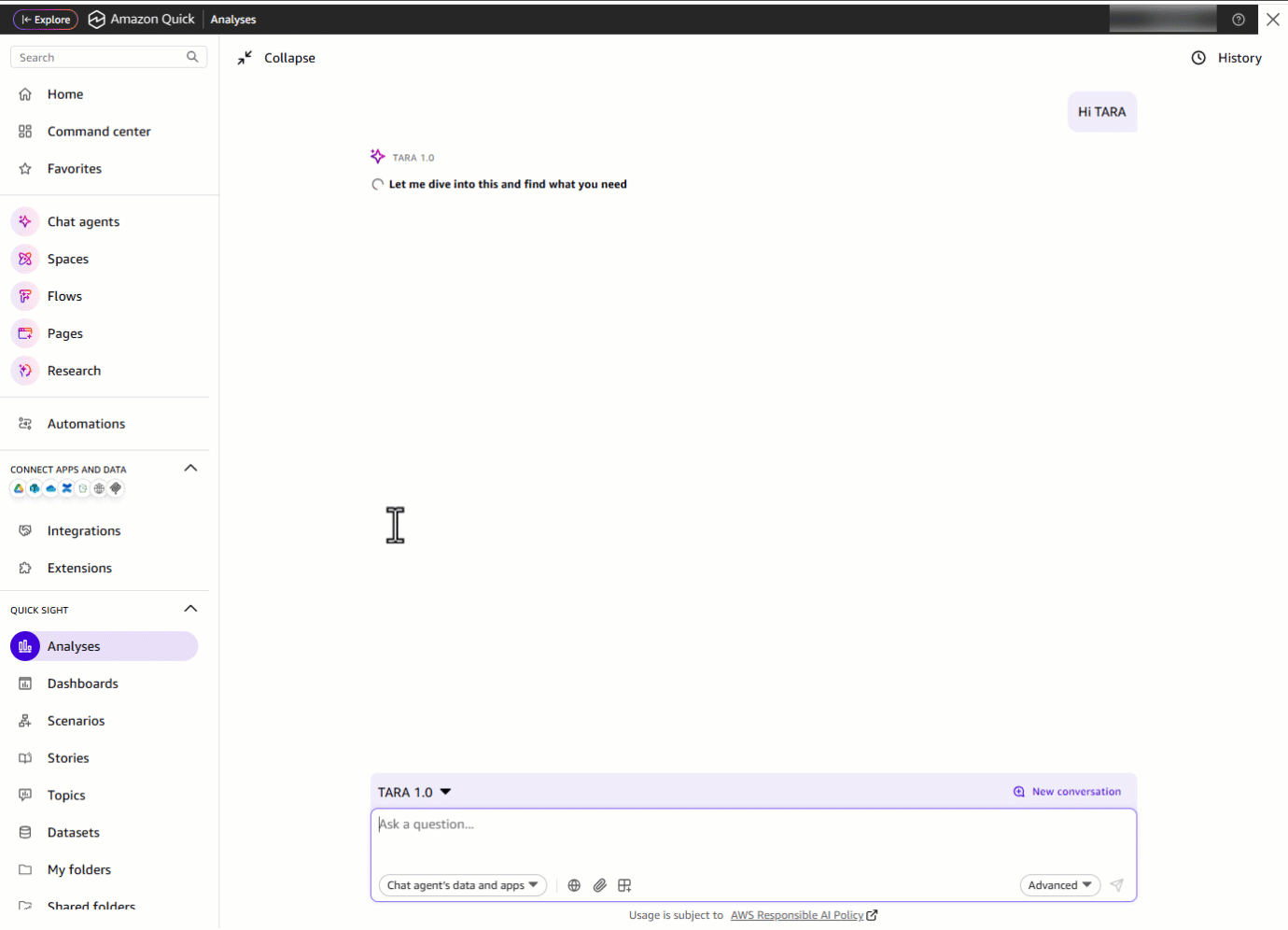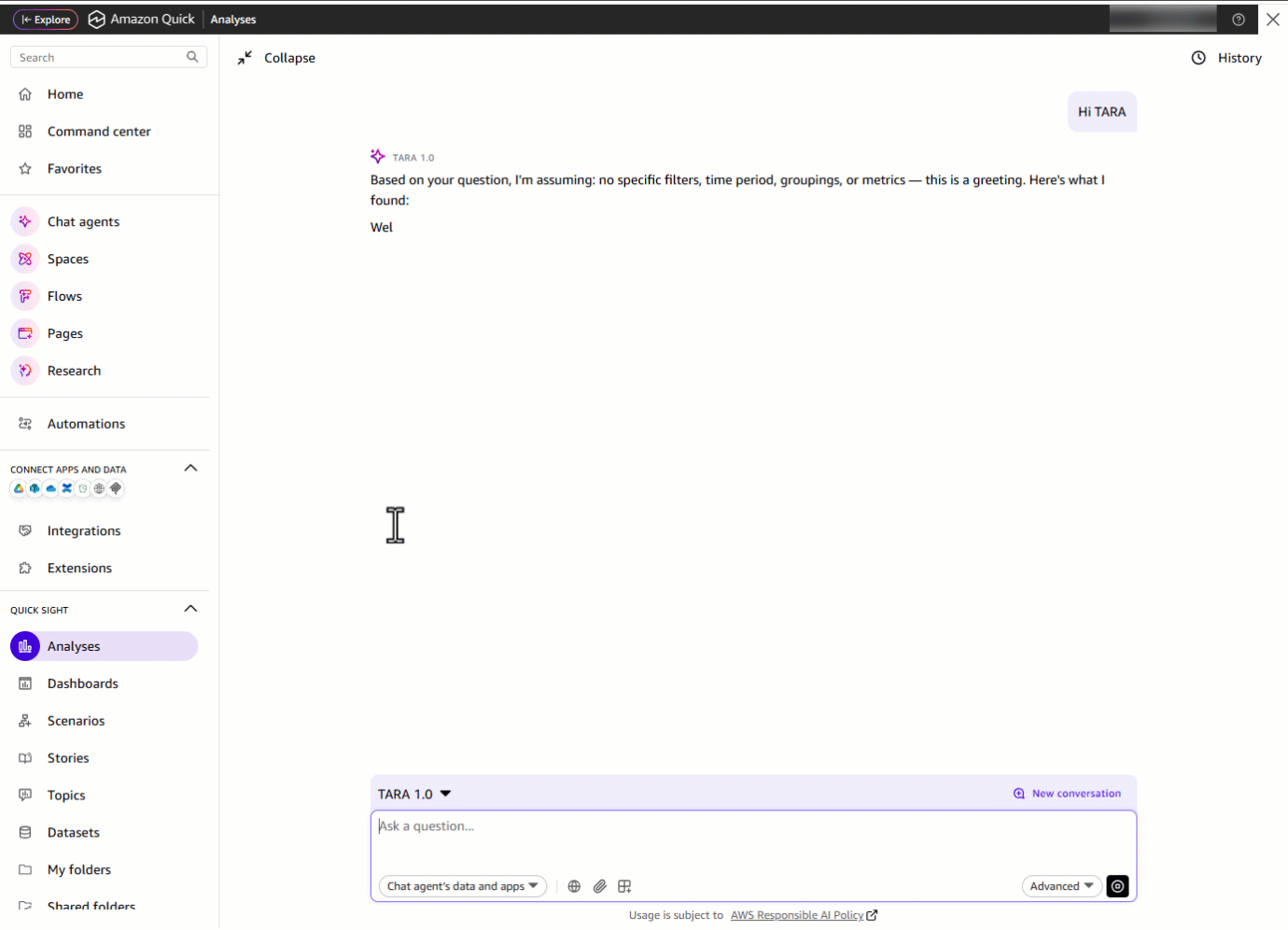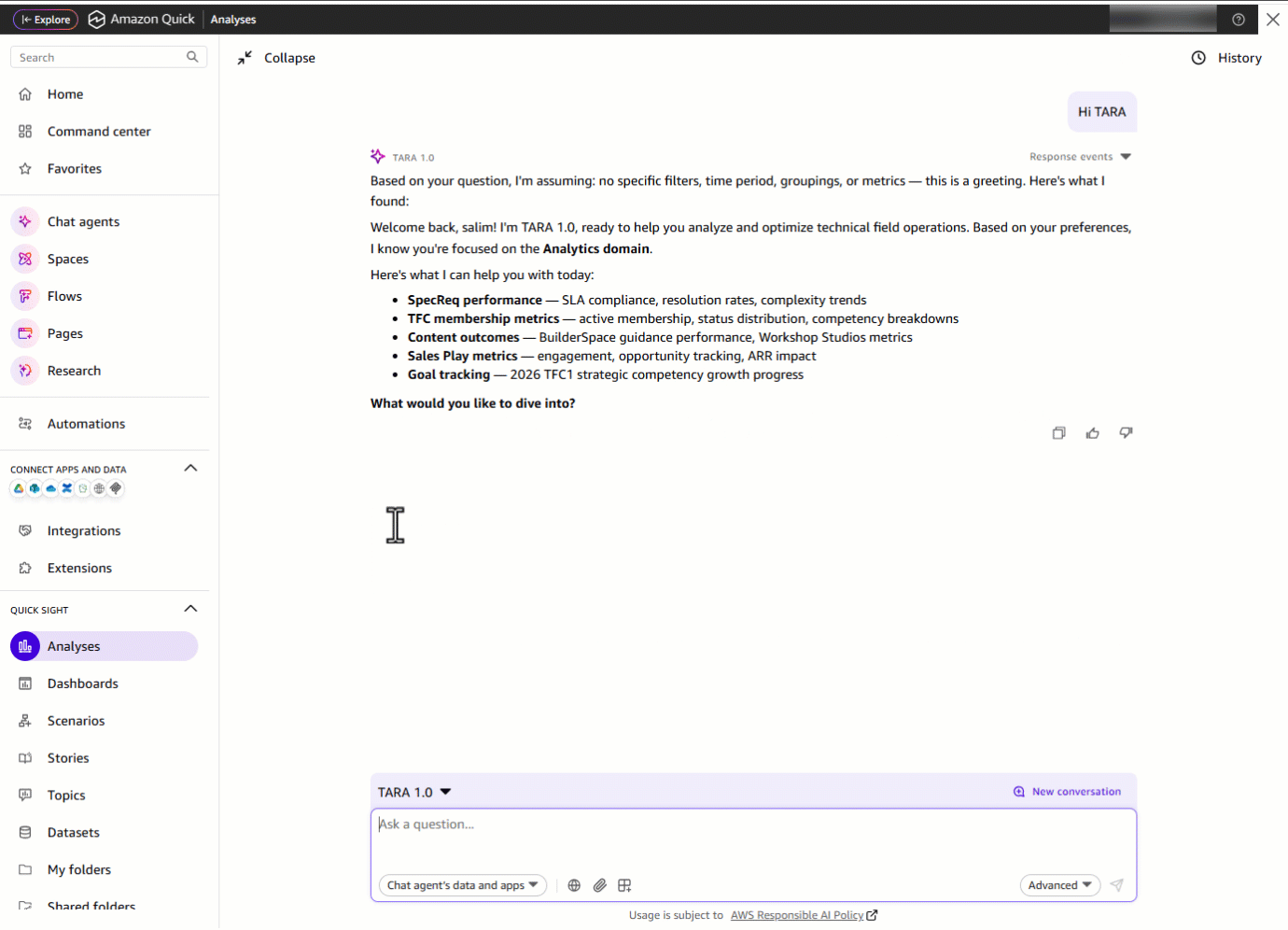
Consider a domain leader who needs to assess their technology domain’s performance. Previously, this meant navigating multiple dashboard tabs, applying filters, and manually piecing together data, a time-consuming process. With TARA, that entire workflow becomes a single conversation.The domain leader opens TARA and starts with a “Hi TARA!”. TARA greets them and immediately surfaces the key data areas available, and more, all accessible from one place.
Enter “Hi TARA!”
Next, they ask: “How is the Analytics domain performing in 2026 YTD?” With one prompt, TARA pulls metrics across multiple datasets. What previously required opening separate dashboards is now a single, consolidated response delivered in seconds.
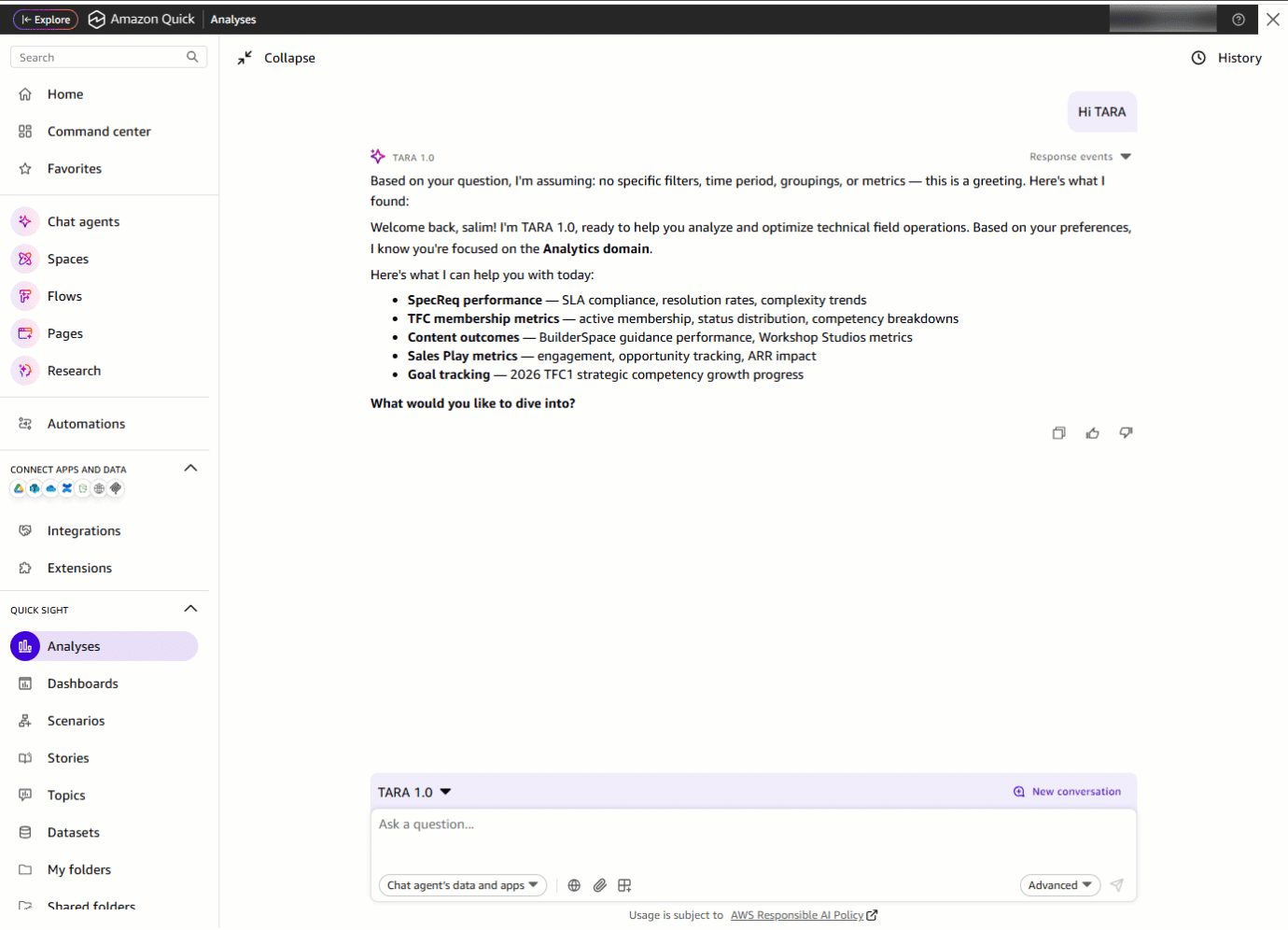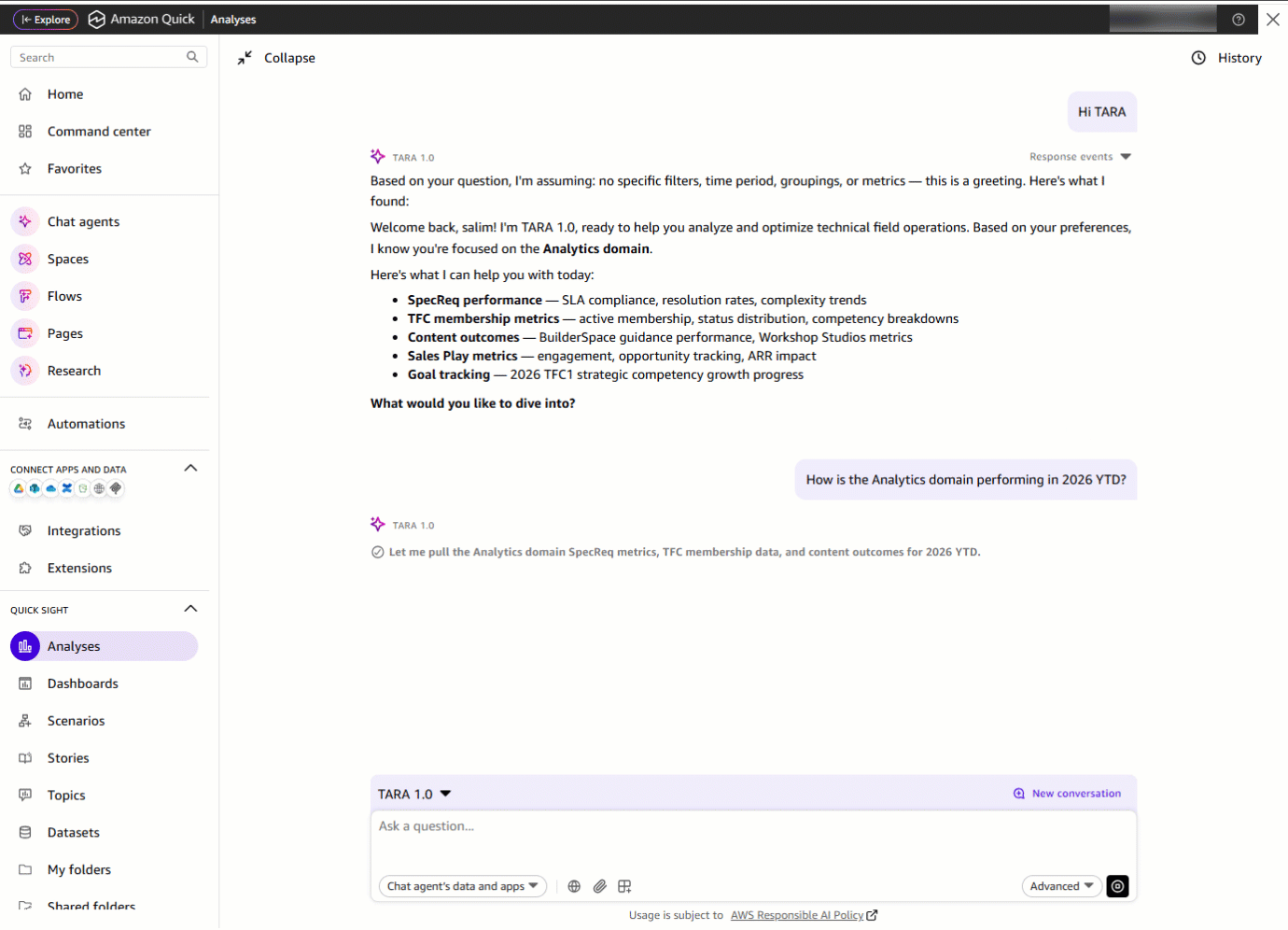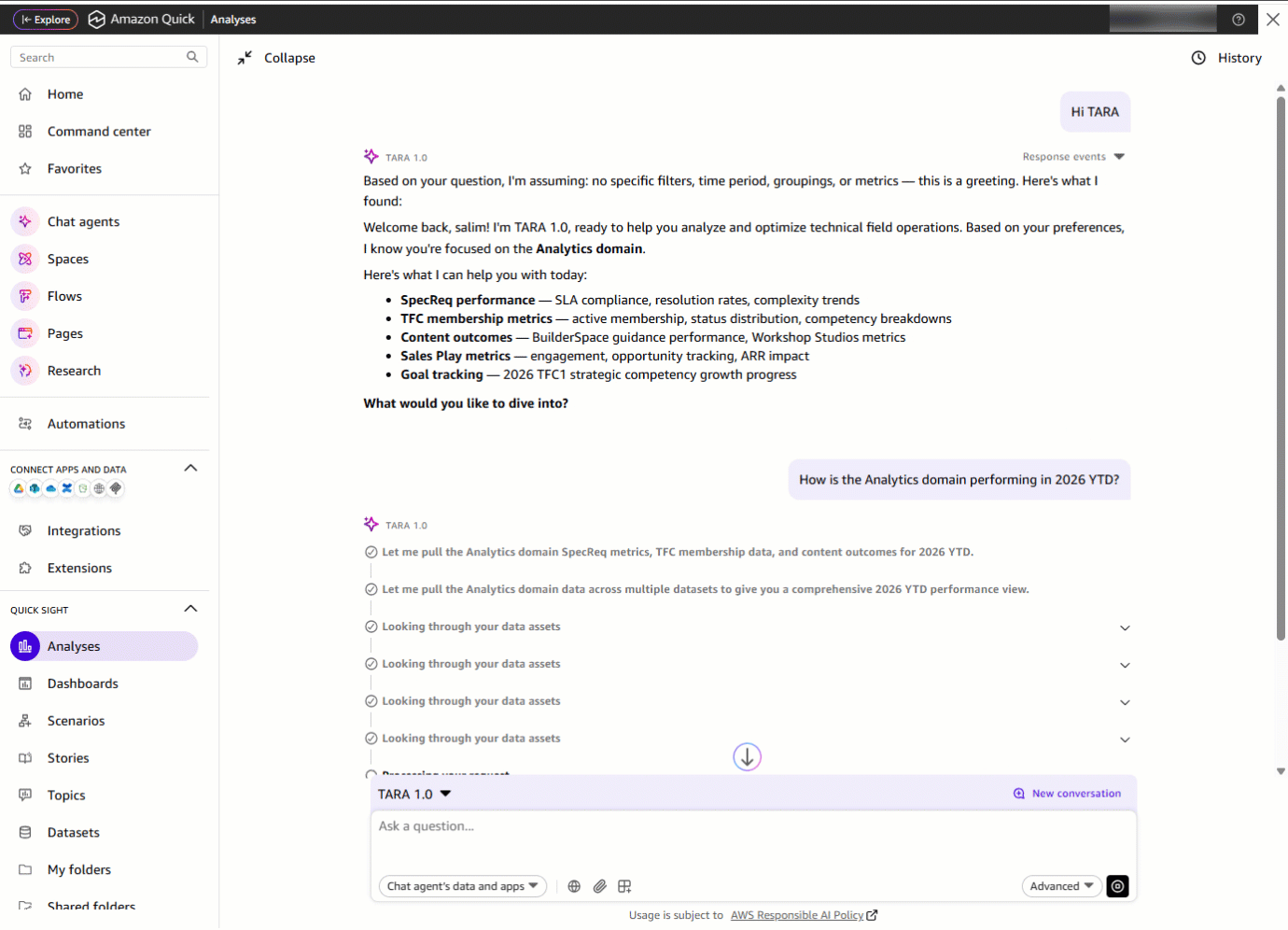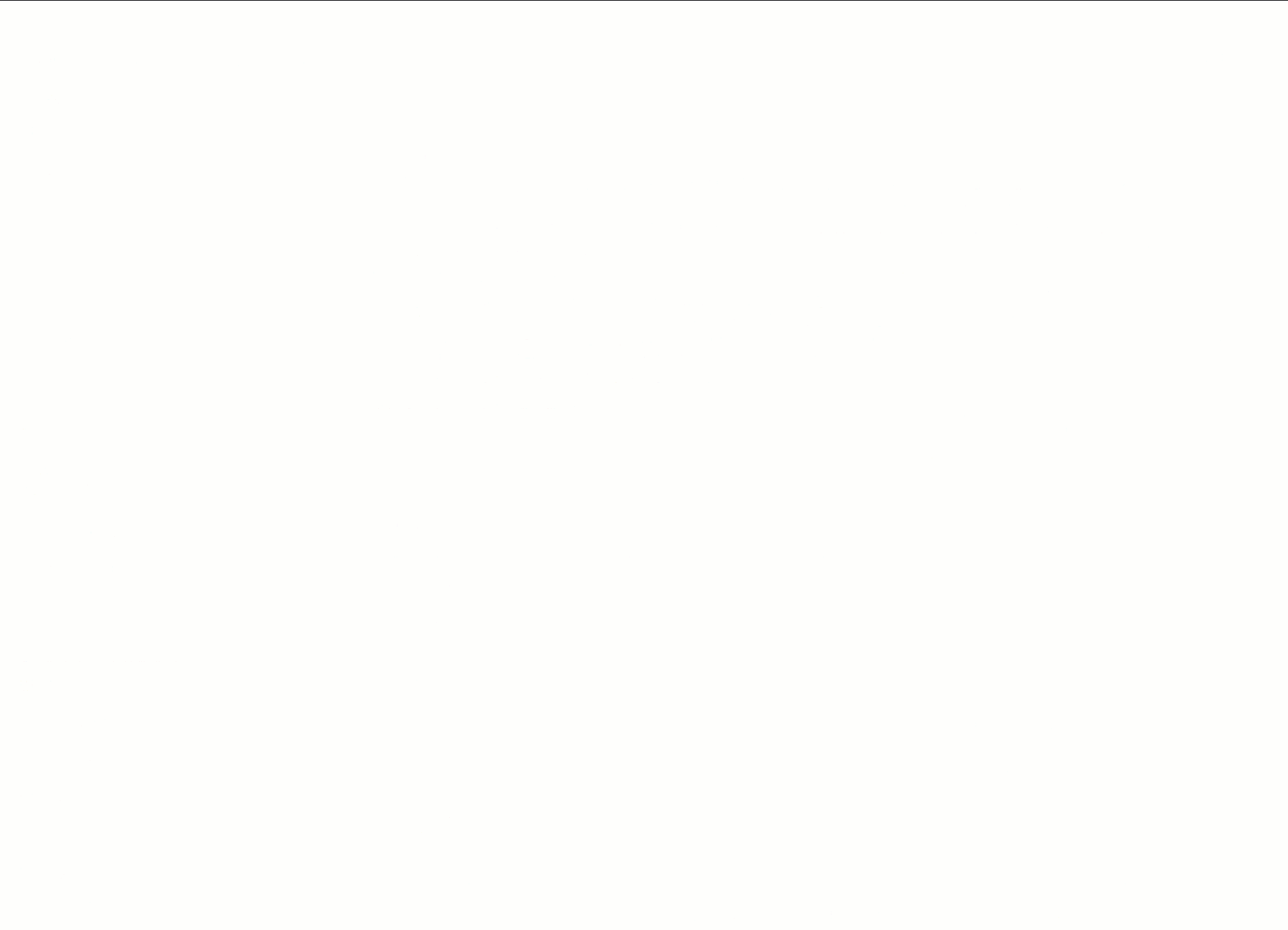
But a domain leader doesn’t operate in isolation, they need context. They ask: “Can you compare the SpecReq performance to other domains and also highlight top primary topics along with the geo breakdown?” Instead of switching between dashboard tabs, re-applying filters for each domain, and manually building a comparison spreadsheet, TARA delivers a cross-domain comparison table showing how Analytics stacks up on metrics, alongside the most requested primary topics (sub-domain within a domain), geographic distribution and domains.
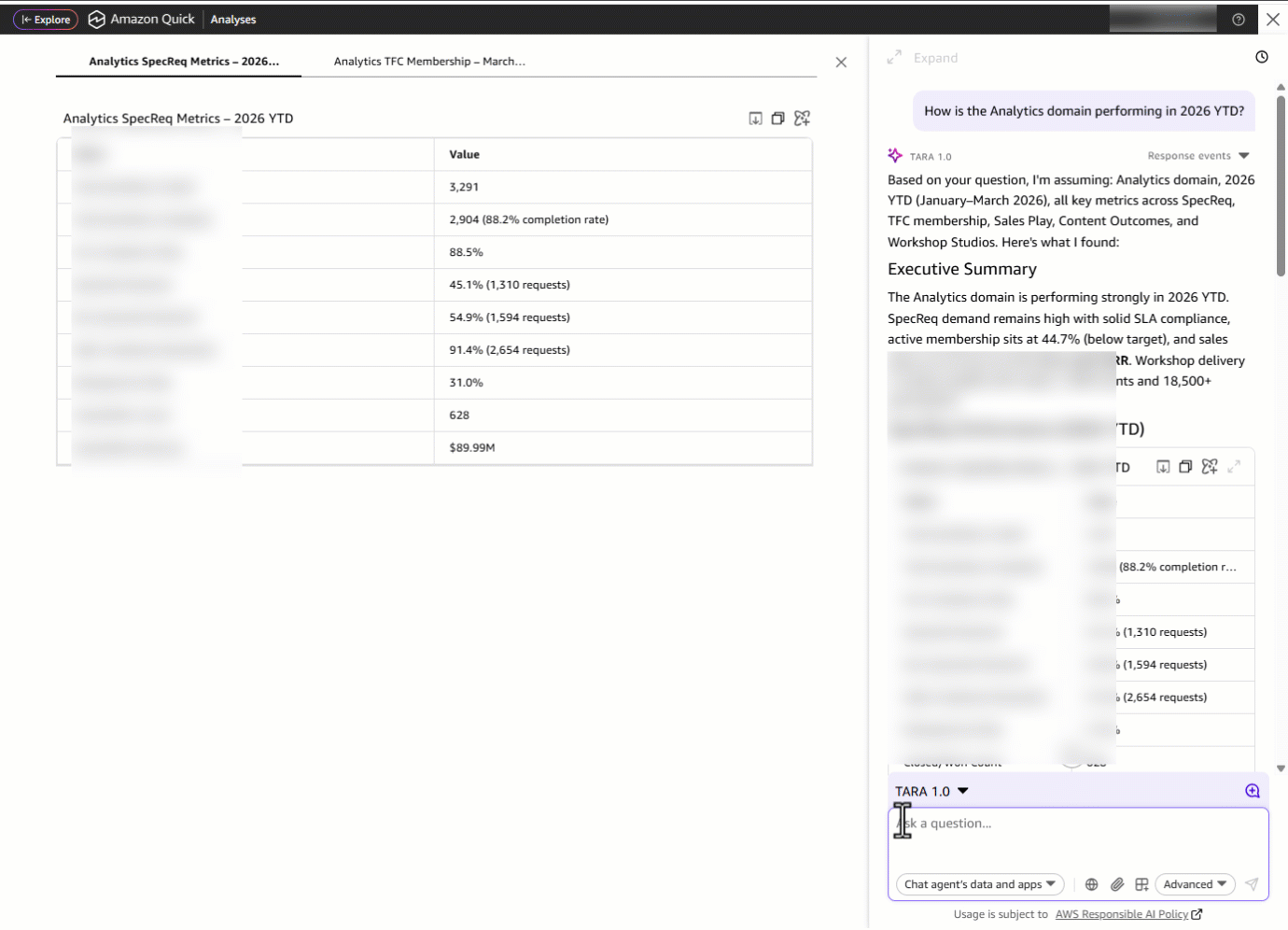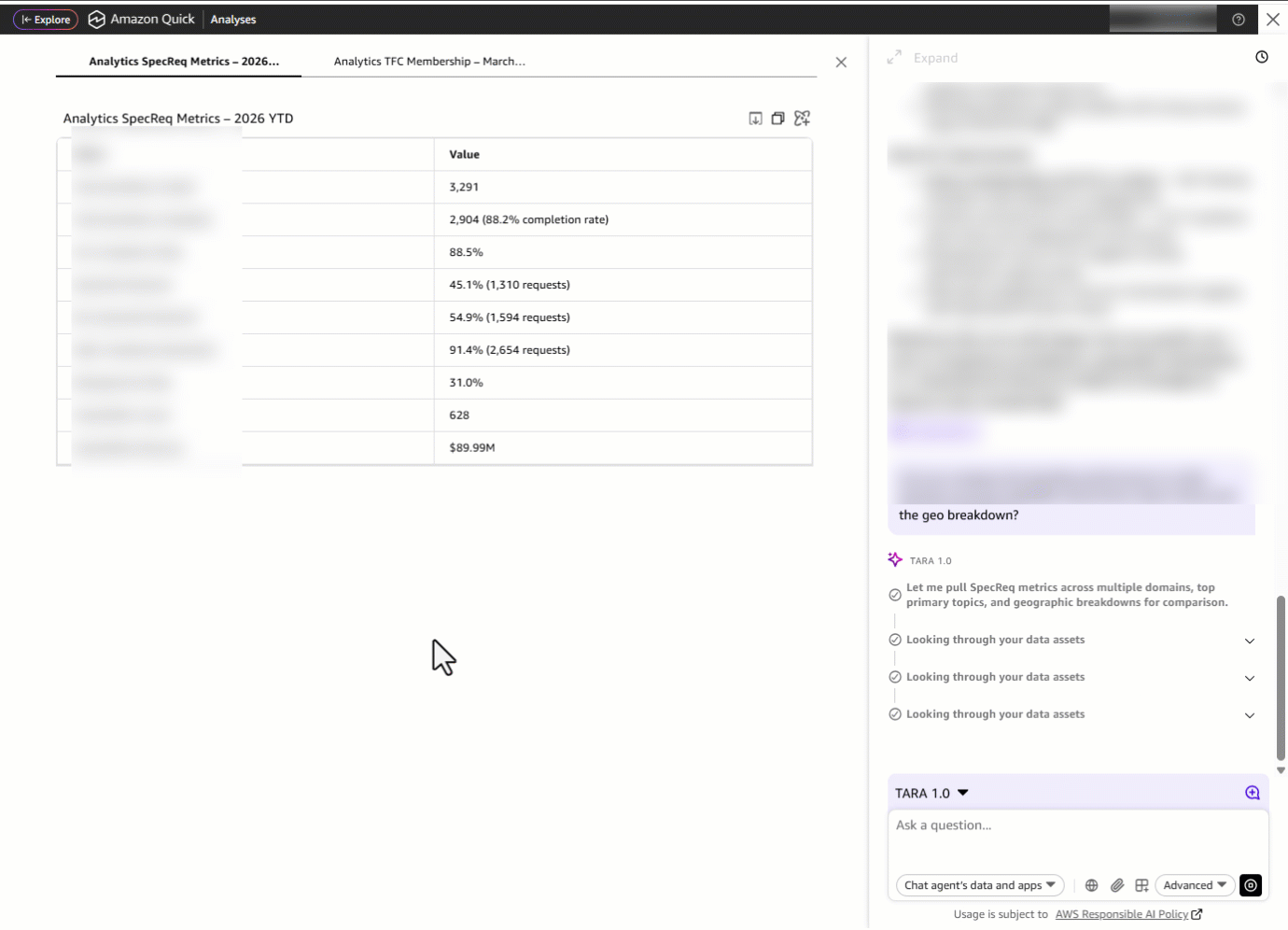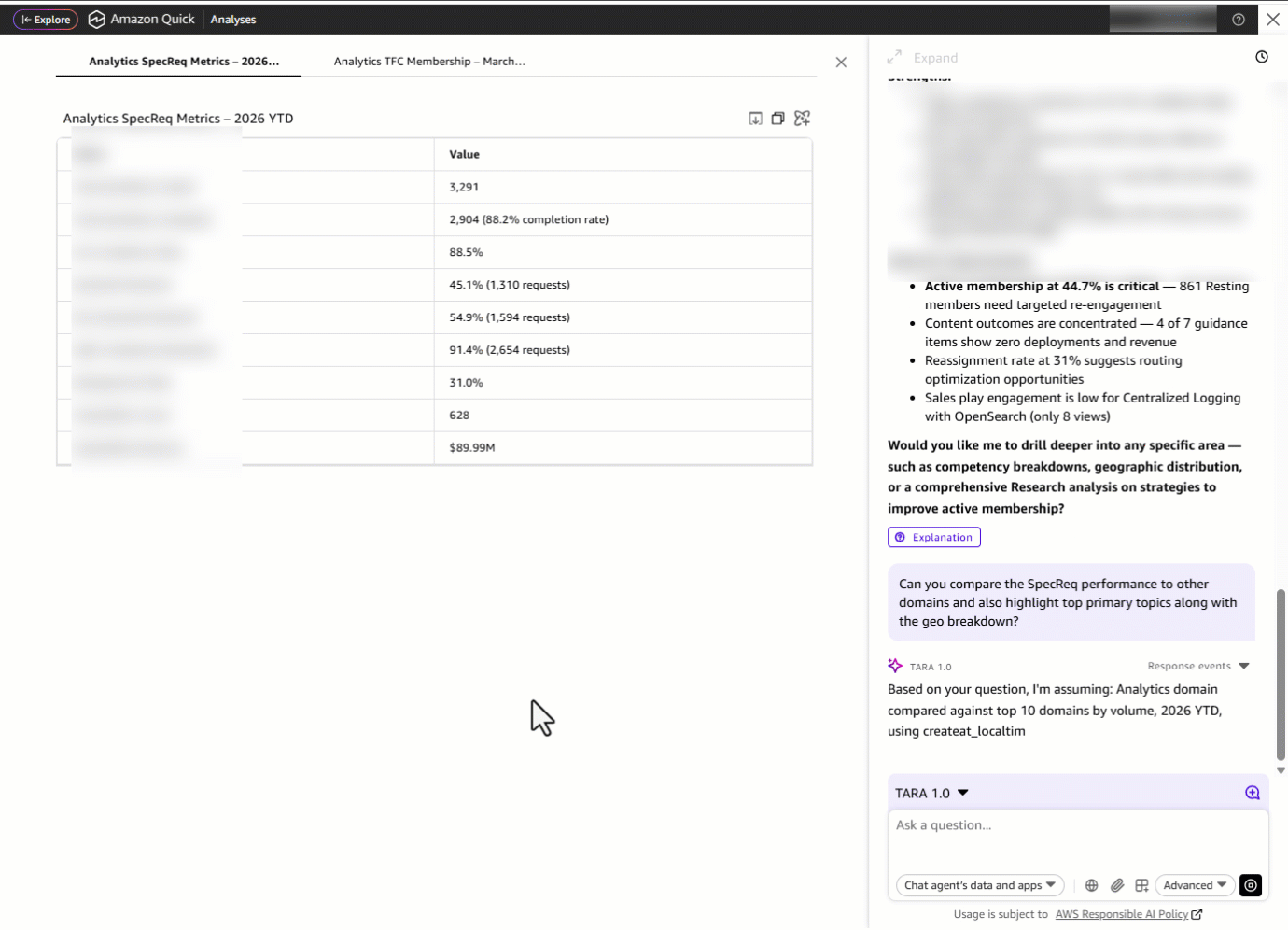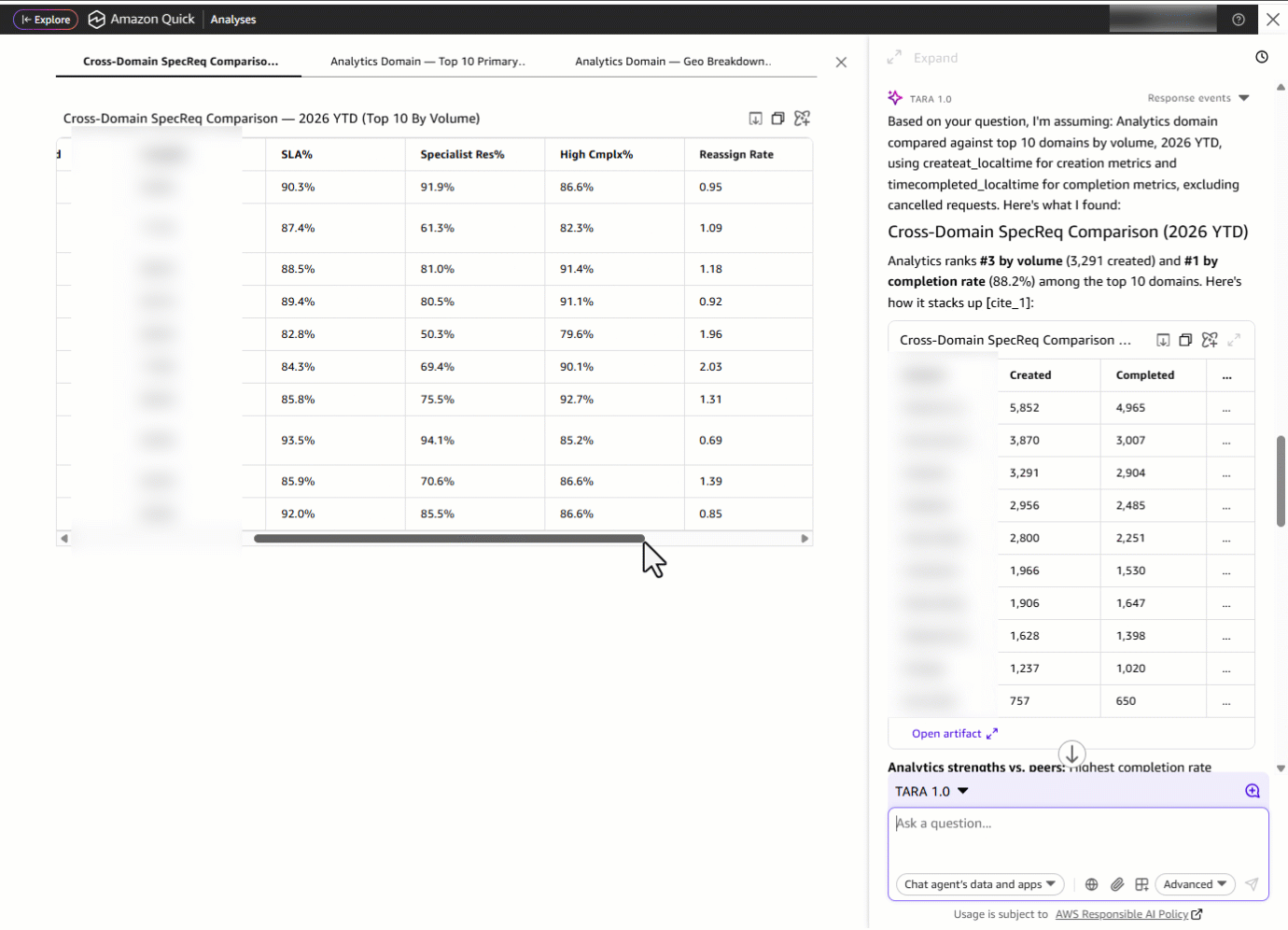
Something catches their eye: the SLA metric is showing strong performance at 92.7 percent. Is this a recent improvement, or has it been consistent? They ask: “Deep dive into the SLA trends for the last 15 months.” TARA surfaces a month-by-month SLA trend line from January 2025—March 2026, revealing whether the current performance is a sustained trajectory or a recent spike, so the domain leader can confidently report on progress or flag emerging risks.
But TARA doesn’t just surface the trend, it shows its work. Alongside the visualization, an expandable explanation panel breaks down exactly how each data point was calculated: the underlying formula (SLA Met ÷ Total SpecReqs), the specific filters applied, volume context, and year-over-year comparisons. This built-in explainability means the domain leader can trace the 3.0 percentage-point improvement back to the raw data, verify assumptions, and walk into their leadership review with full confidence in the story behind the metric.

Each response is powered by Amazon Quick’s direct dataset Q&A, which translates natural language into real-time SQL queries against the underlying data, delivering formatted analytics and visualizations in seconds.
Key Architectural Differentiator:
The critical shift from Topics-based Q&A to direct dataset Q&A is the removal of the semantic intermediary. With Topics, every field, relationship, synonym, and aggregation rule had to be manually defined and maintained in a semantic model before users could query the data. Direct dataset Q&A bypasses this layer entirely where the system reads the dataset schema at query time, infers relationships from the data structure, and generates SQL dynamically. This means:
- New columns are immediately queryable without configuration updates
- Cross-dataset queries are resolved automatically based on shared keys and column names
- Business logic is applied contextually rather than through rigid, pre-defined rules
- Maintenance overhead drops to near zero as the system adapts to schema changes organically
This architectural approach enabled TARA to scale from supporting a handful of pre-modeled query patterns to handling thousands of unique, multi-dimensional questions across the SDL team’s full data portfolio.
Results and impact
After implementing the direct Dataset Q&A capability, the SDL team measured the following improvements using a combination of system telemetry, structured ground truth testing, and operational support metrics collected before and after rollout:
- Query success rate: Increased from a range of 80–85 percent to more than 95 percent, based on the percentage of user queries that returned accurate, usable responses without requiring rephrasing, analyst intervention, or manual query correction.
- Average query resolution time: Reduced from roughly 90 minutes to under 5 minutes for complex multidimensional questions, measured by comparing the full time required to answer representative business questions before and after TARA’s conversational Dataset Q&A experience.
- Maintenance overhead: Bypassed 2–3 days per month previously spent updating semantic definitions, refining mappings, and maintaining business logic to support evolving reporting needs.
- User adoption: More than 15,000 TFC members and AWS leaders now access analytics through natural language queries, based on active usage across TARA.
Program leaders can now answer strategic questions in minutes instead of hours. The system also handles complex scenarios that previously required manual data aggregation, validation, and calculation.
Clean up
To avoid incurring ongoing charges, delete the Spaces, Actions, MCP integrations, chat agents and other Quick assets that you created as part of experimentation. For instructions, see the Amazon Quick documentation.
Conclusion
Direct dataset Q&A transforms how users interact with data by alleviating configuration overhead and enabling dynamic query generation. The approach delivers the immediate query ability of complex datasets without semantic modeling, applies business logic contextually at runtime, supports sophisticated multi-dimensional analysis through natural language, and maintains alignment with enterprise security policies—all while significantly reducing maintenance. This architectural shift enabled TARA to scale from handling predefined query patterns to supporting thousands of unique analytical questions across the SDL team’s complete data portfolio. Get started with Dataset Q&A today using the following resources:
About the authors



{kind=link}