


At a glance
- AI benchmarks report performance on specific tasks but provide limited insight into underlying capabilities; ADeLe evaluates models by scoring both tasks and models across 18 core abilities, enabling direct comparison between task demands and model capabilities.
- Using these ability scores, the method predicts performance on new tasks with ~88% accuracy, including for models such as GPT-4o and Llama-3.1.
- It builds ability profiles and identifies where models are likely to succeed or fail, highlighting strengths and limitations across tasks.
- By linking outcomes to task demands, ADeLe explains differences in performance, showing how it changes as task complexity increases.
AI benchmarks report how large language models (LLMs) perform on specific tasks but provide little insight into their underlying capabilities that drive their performance. They do not explain failures or reliably predict outcomes on new tasks. To address this, Microsoft researchers in collaboration with Princeton University and Universitat Politècnica de València introduce ADeLe (opens in new tab) (AI Evaluation with Demand Levels), a method that characterizes both models and tasks using a broad set of capabilities, such as reasoning and domain knowledge, so performance on new tasks can be predicted and linked to specific strengths and weaknesses in a model.
In a paper published in Nature, “General Scales Unlock AI Evaluation with Explanatory and Predictive Power (opens in new tab),” the team describes how ADeLe moves beyond aggregate benchmark scores. Rather than treating evaluation as a collection of isolated tests, it represents both benchmarks and LLMs using the same set of capability scores. These scores can then be used to estimate how a model will perform on tasks it has not encountered before. The research was supported by Microsoft’s Accelerating Foundation Models Research (AFMR) grant program.
ADeLe-based evaluation
ADeLe scores tasks across 18 core abilities, such as attention, reasoning, domain knowledge, and assigns each task a value from 0 to 5 based on how much it requires each ability. For example, a basic arithmetic problem might score low on quantitative reasoning, but an Olympiad-level proof would score much higher.
Evaluating a model across many such tasks produces an ability profile—a structured view of where the model performs and where it breaks down. Comparing this profile to the demands of a new task makes it possible to identify the specific gaps that lead to failure. The process is illustrated in Figure 1.
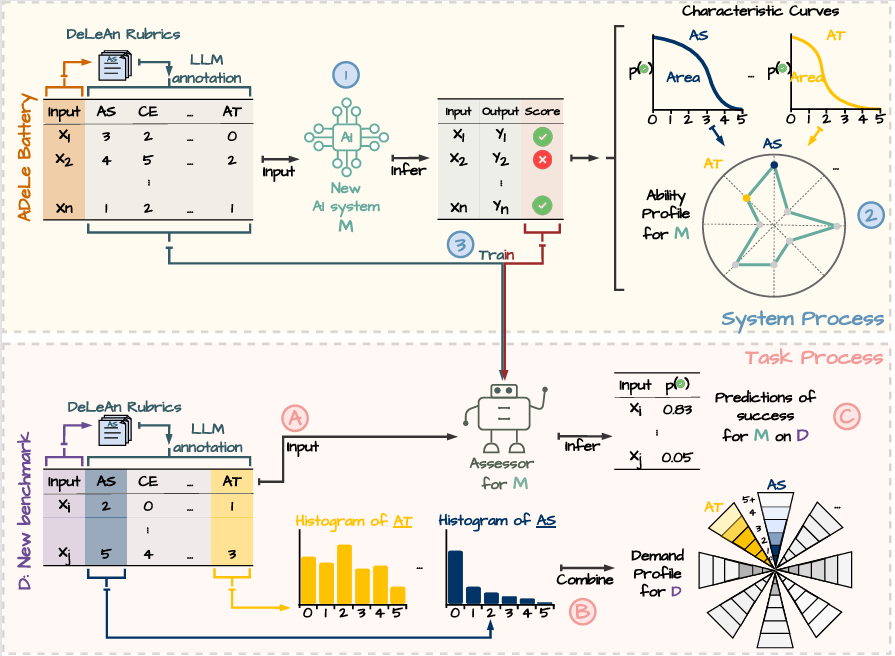
Evaluating ADeLe
Using ADeLe, the team evaluated a range of AI benchmarks and model behaviors to understand what current evaluations capture and what they miss. The results show that many widely used benchmarks provide an incomplete and sometimes misleading picture of model capabilities and that a more structured approach can clarify those gaps and help predict how models will behave in new settings.
ADeLe shows that many benchmarks do not isolate the abilities they are intended to measure or only cover a limited range of difficulty levels. For example, a test designed to evaluate logical reasoning may also depend heavily on specialized knowledge or metacognition. Others focus on a narrow range of difficulty, omitting both simpler and more complex cases. By scoring tasks based on the abilities they require, ADeLe makes these mismatches visible and provides a way to diagnose existing benchmarks and design better ones.
Applying this framework to 15 LLMs, the team constructed ability profiles using 0–5 scores for each of 18 abilities. For each ability, the team measured how performance changes with task difficulty and used the difficulty level at which the model has a 50% chance of success as its ability score. Figure 2 illustrates these results as radial plots that show where the model performs well and where it breaks down.
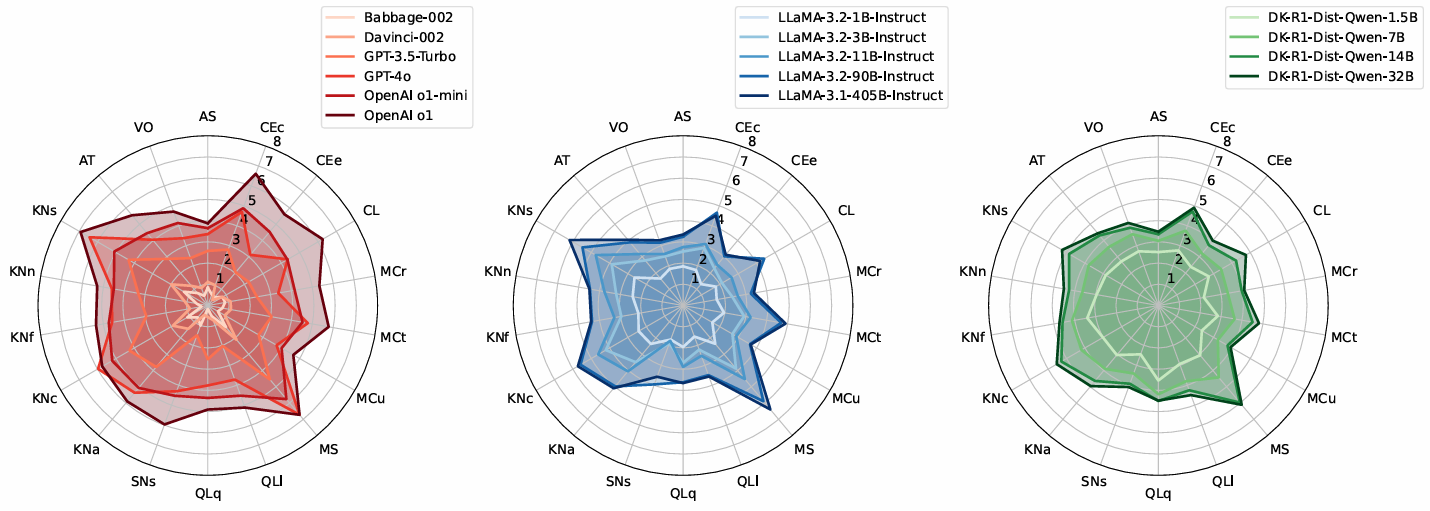
This analysis shows that models differ in their strengths and weaknesses across abilities. Newer models generally outperform older ones, but not consistently across all abilities. Performance on knowledge-heavy tasks depends strongly on model size and training, while reasoning-oriented models show clear gains on tasks requiring logic, learning, abstraction, and social inference. These patterns typically require multiple, separate analyses across different benchmarks and can still produce conflicting conclusions when task demands are not carefully controlled. ADeLe surfaces them within a single framework.
ADeLe also enables prediction. By comparing a model’s ability profile to the demands of a task, it can forecast whether the model will succeed, even on tasks that are unfamiliar. In experiments, this approach achieved approximately 88% accuracy for models like GPT-4o and LLaMA-3.1-405B, outperforming traditional methods. This makes it possible to both explain and anticipate potential failures before deployment, improving the reliability and predictability of AI model assessment.
Whether AI systems can truly reason is a central debate in the field. Some studies report strong reasoning performance, while others show they break down at scale. These results reflect differences in task difficulty. ADeLe shows that benchmarks labeled as measuring “reasoning” vary in what they require, from basic problem-solving to tasks that combine the need for advanced logic, abstraction, and domain knowledge. The same model can score above 90% on lower-demand tests and below 15% on more demanding ones, reflecting differences in task requirements rather than a change in capability.
Reasoning-oriented models like OpenAI’s o1 and GPT-5 show measurable gains over standard models—not only in logic and mathematics but also with interpreting user intent. However, performance declines as task demands increase. AI systems can reason, but only up to a point, and ADeLe identifies where that point is for each model.
Azure AI Foundry Labs
Get a glimpse of potential future directions for AI, with these experimental technologies from Microsoft Research.
Looking ahead
ADeLe is designed to evolve alongside advances in AI and can be extended to multimodal and embodied AI systems. It also has the potential to serve as a standardized framework for AI research, policymaking, and security auditing.
More broadly, it advances a more systematic approach to AI evaluation—one that explains system behavior and predicts performance. This work builds on earlier efforts, including Microsoft research on applying psychometrics to AI evaluation and recent work on Societal AI, emphasizing the importance of AI evaluation.
As general-purpose AI systems continue to outpace existing evaluation methods, approaches like ADeLe offer a path toward more rigorous and transparent assessment in real-world use. The research team is working to expand this effort through a broader community. Additional experiments, benchmark annotations, and resources are available on GitHub (opens in new tab).




{kind=link}