


The Semantic Telemetry Project aims to better understand complex, turn-based human-AI interactions in Microsoft Copilot using a new data science approach.
This understanding is crucial for recognizing how individuals utilize AI systems to address real-world tasks. It provides actionable insights, enhances key use cases , and identifies opportunities for system improvement.
In a recent blog post, we shared our approach for classifying chat log data using large language models (LLMs), which allows us to analyze these interactions at scale and in near real time. We also introduced two of our LLM-generated classifiers: Topics and Task Complexity.
This blog post will examine how our suite of LLM-generated classifiers can serve as early indicators for user engagement and highlight how usage and satisfaction varies based on AI and user expertise.
The key findings from our research are:
- When users engage in more professional, technical, and complex tasks, they are more likely to continue utilizing the tool and increase their level of interaction with it.
- Novice users currently engage in simpler tasks, but their work is gradually becoming more complex over time.
- More expert users are satisfied with AI responses only where AI expertise is on par with their own expertise on the topic, while novice users had low satisfaction rates regardless of AI expertise.
Read on for more information on these findings. Note that all analyses were conducted on anonymous Copilot in Bing interactions containing no personal information.
Classifiers mentioned in article:
Knowledge work classifier: Tasks that involve creating artifacts related to information work typically requiring creative and analytical thinking. Examples include strategic business planning, software design, and scientific research.
Task complexity classifier: Assesses the cognitive complexity of a task if a user performs it without the use of AI. We group into two categories: low complexity and high complexity.
Topics classifier: A single label for the primary topic of the conversation.
User expertise: Labels the user’s expertise on the primary topic within the conversation as one of the following categories: Novice (no familiarity with the topic), Beginner (little prior knowledge or experience), Intermediate (some basic knowledge or familiarity with the topic), Proficient (can apply relevant concepts from conversation), and Expert (deep and comprehensive understanding of the topic).
AI expertise: Labels the AI agent expertise based on the same criteria as user expertise above.
User satisfaction: A 20-question satisfaction/dissatisfaction rubric that the LLM evaluates to create an aggregate score for overall user satisfaction.
What keeps Bing Chat users engaged?
We conducted a study of a random sample of 45,000 anonymous Bing Chat users during May 2024. The data was grouped into three cohorts based on user activity over the course of the month:
- Light (1 active chat session per week)
- Medium (2-3 active chat sessions per week)
- Heavy (4+ active chat sessions per week)
The key finding is that heavy users are doing more professional, complex work.
We utilized our knowledge work classifier to label the chat log data as relating to knowledge work tasks. What we found is knowledge work tasks were higher in all cohorts, with the highest percentage in heavy users.
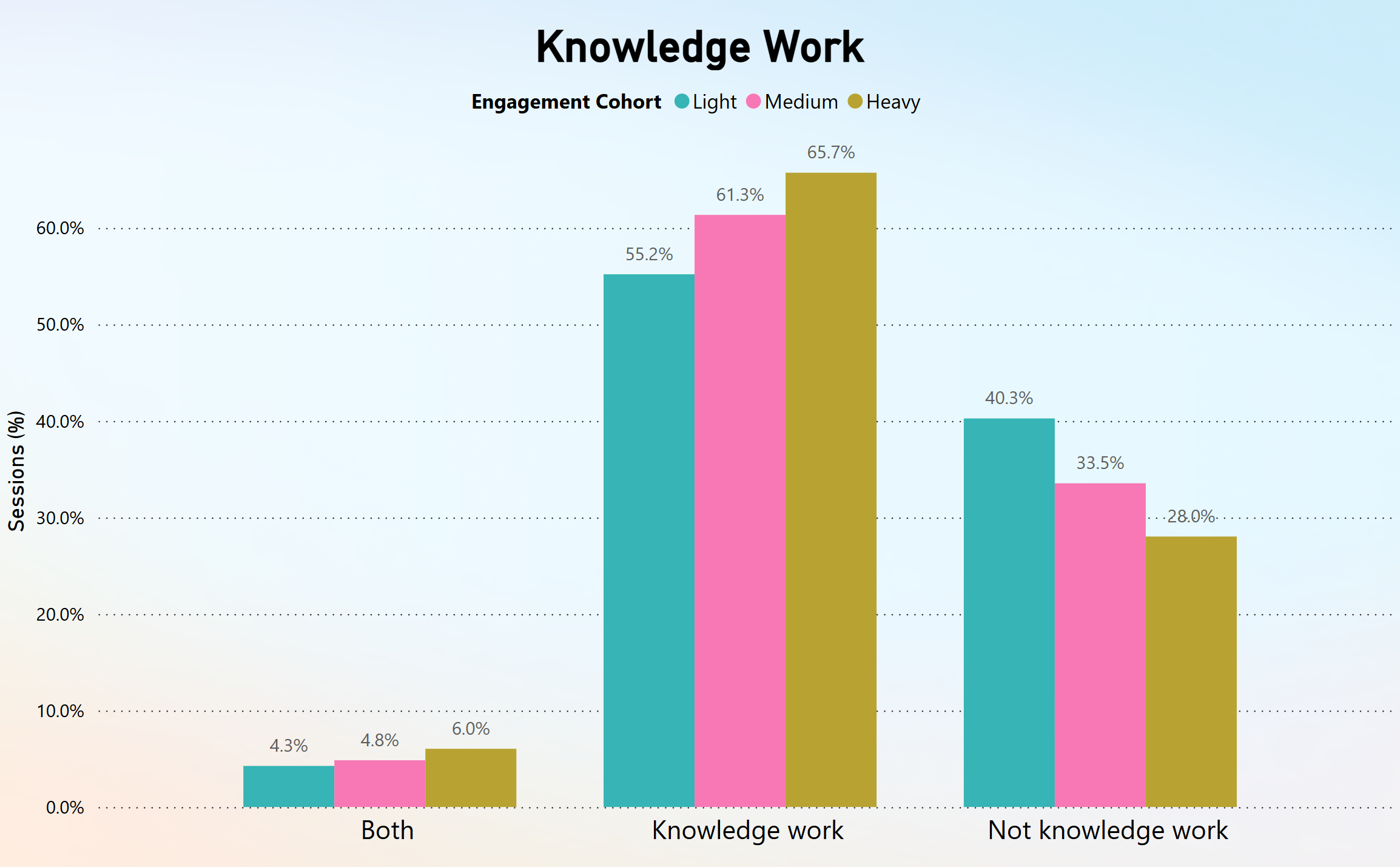
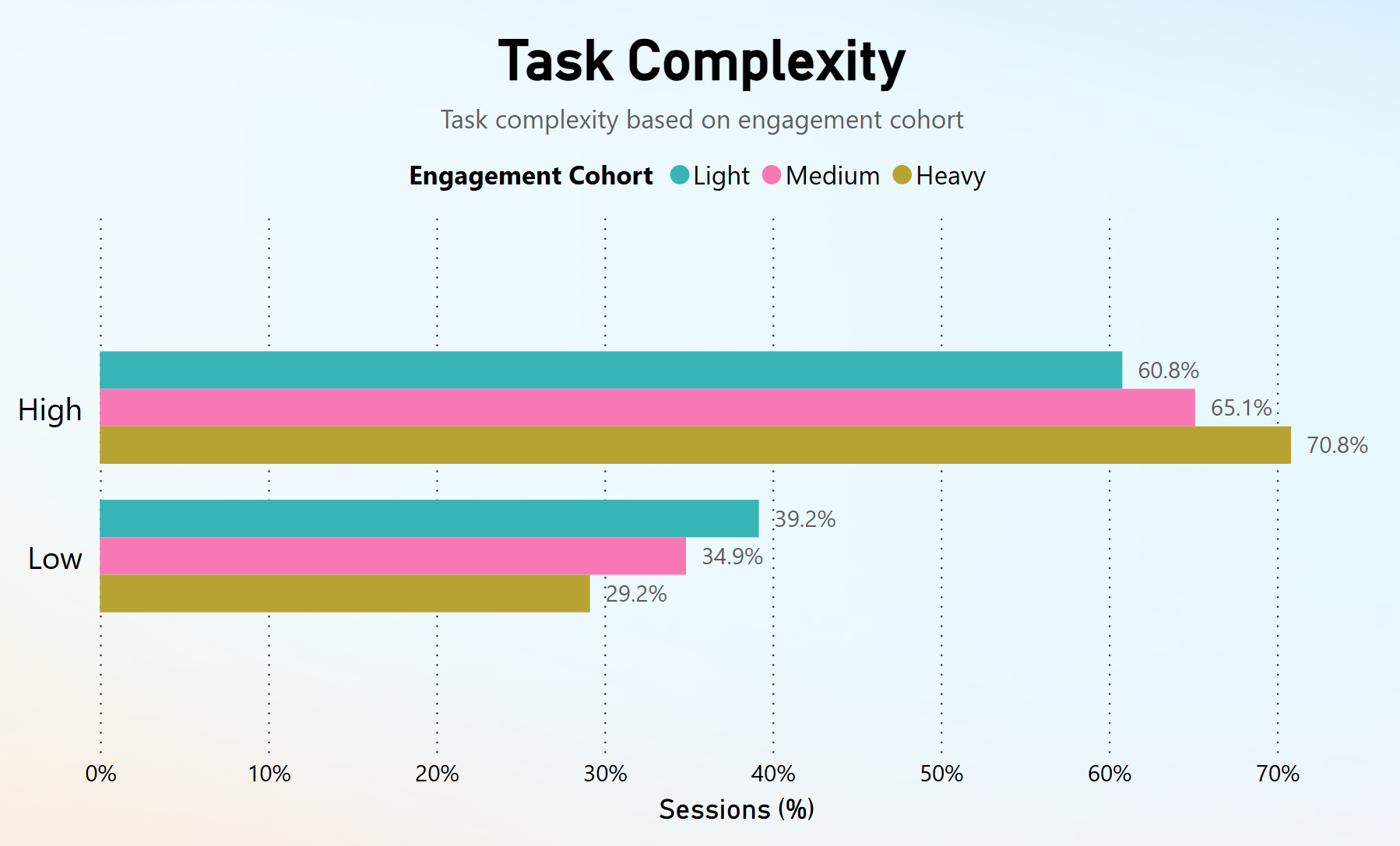
Analyzing task complexity, we observed that users with higher engagement frequently perform the highest number of tasks with high complexity, while users with lower engagement performed more tasks with low complexity.
Looking at the overall data, we can filter on heavy users and see higher numbers of chats where the user was performing knowledge work tasks. Based on task complexity, we see that most knowledge work tasks seek to apply a solution to an existing problem, primarily within programming and scripting. This is in line with our top overall topic, technology, which we discussed in the previous post.
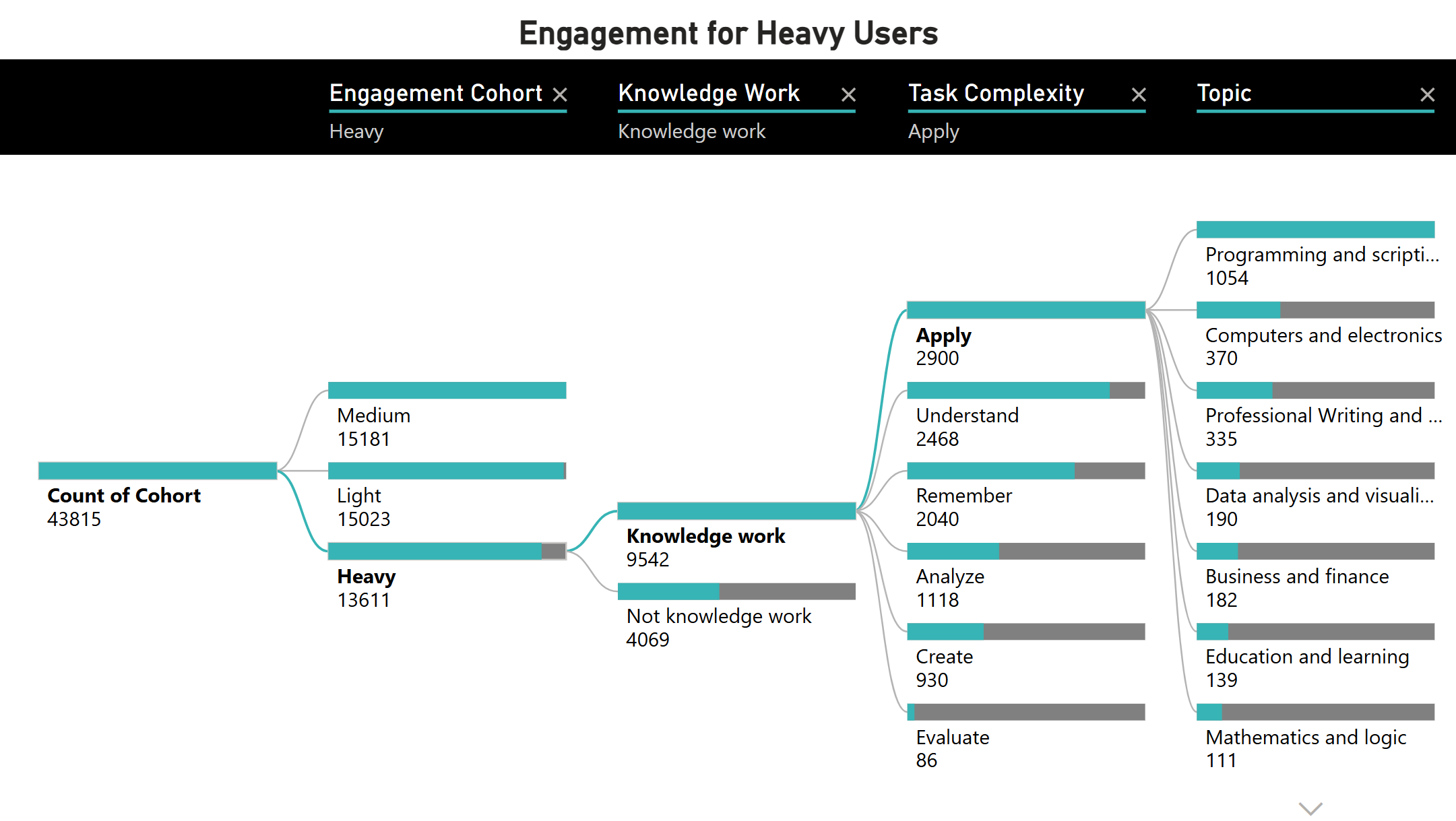
In contrast, light users tended to do more low complexity tasks (“Remember”), using Bing Chat like a traditional search engine and engaging more in topics like business and finance and computers and electronics.

Novice queries are becoming more complex
We looked at Bing Chat data from January through August 2024 and we classified chats using our User Expertise classifier. When we looked at how the different user expertise groups were using the tool for professional tasks, we discovered that proficient and expert users tend to do more professional tasks with high complexity in topics like programming and scripting, professional writing and editing, and physics and chemistry.
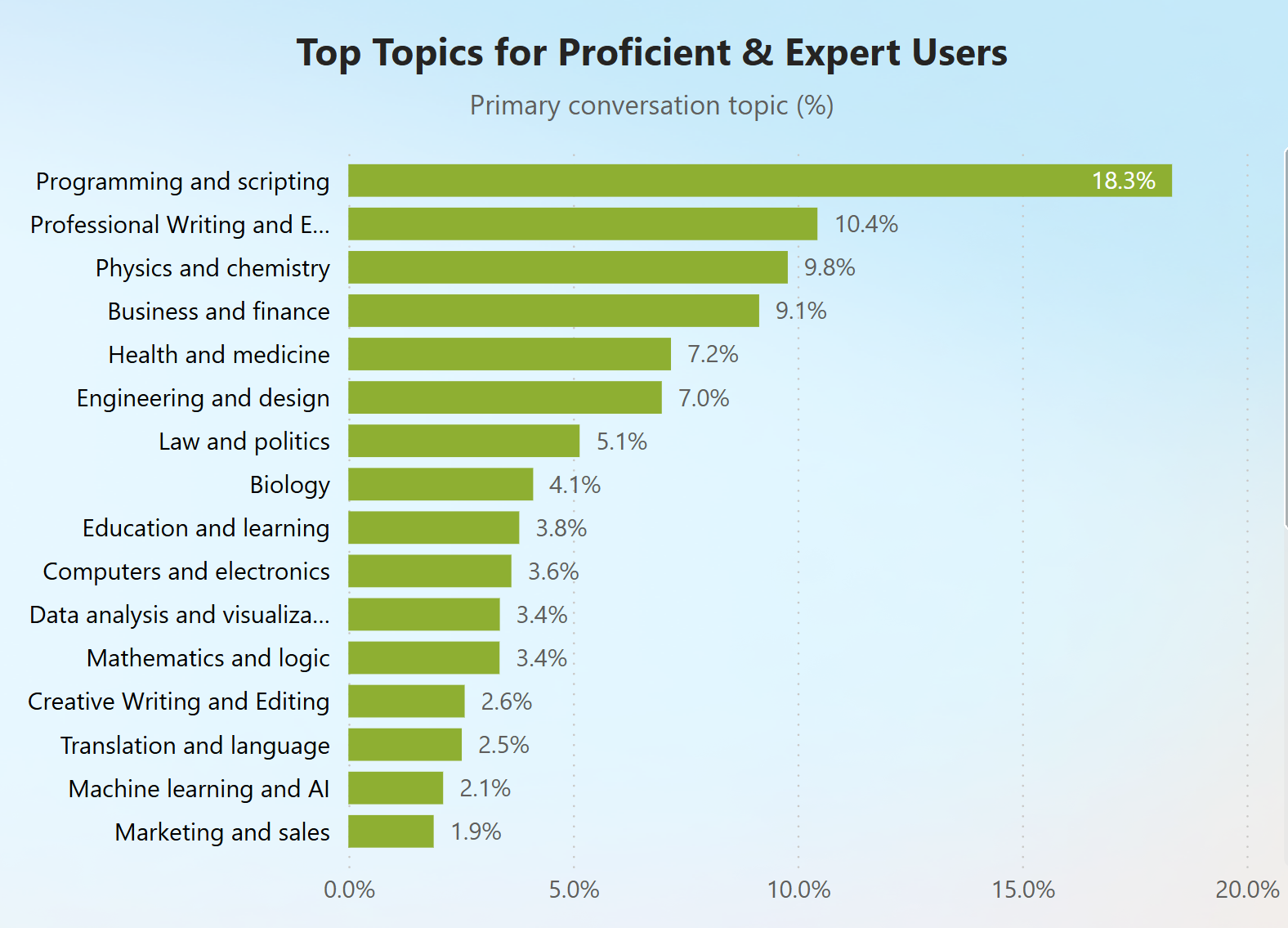
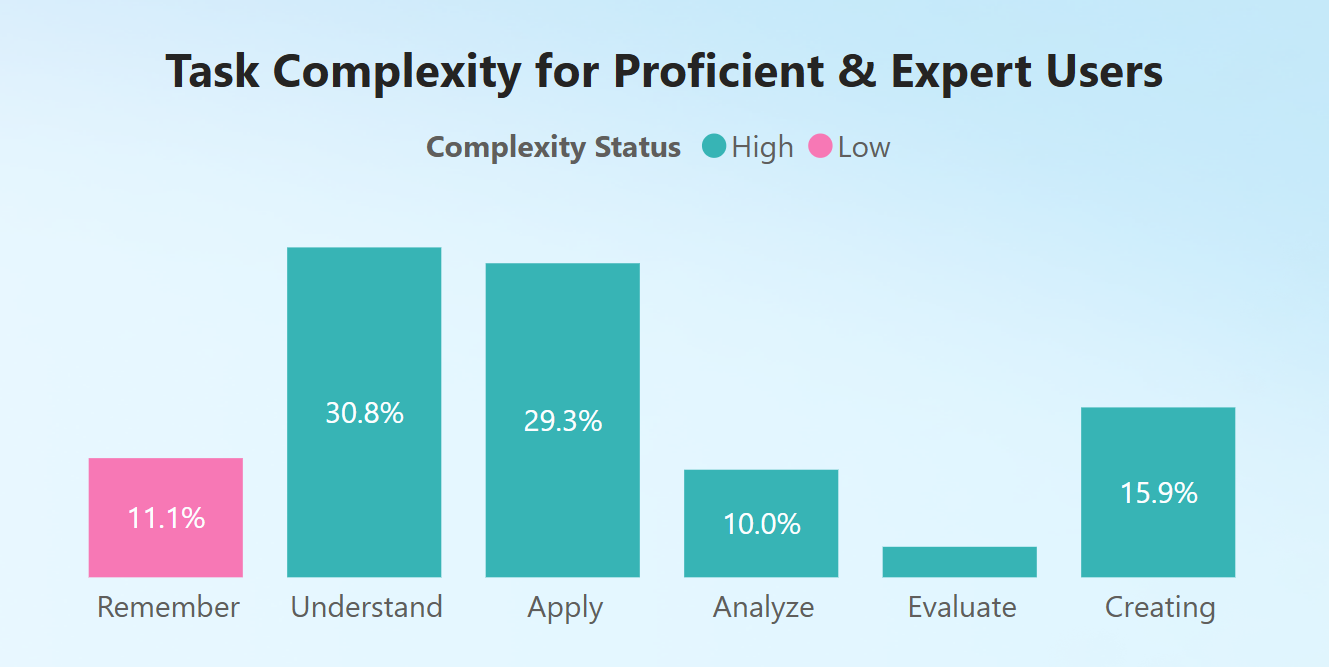
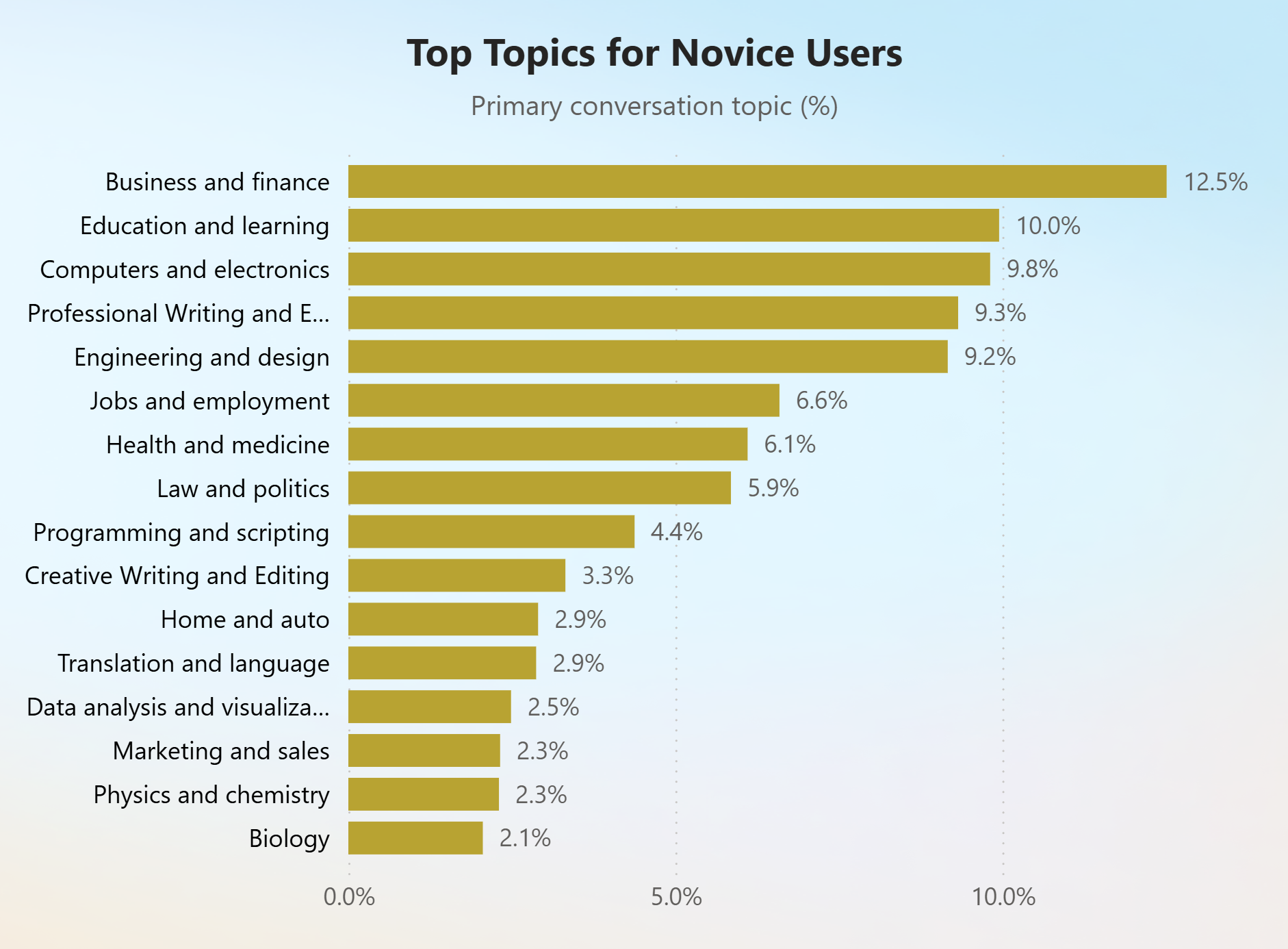
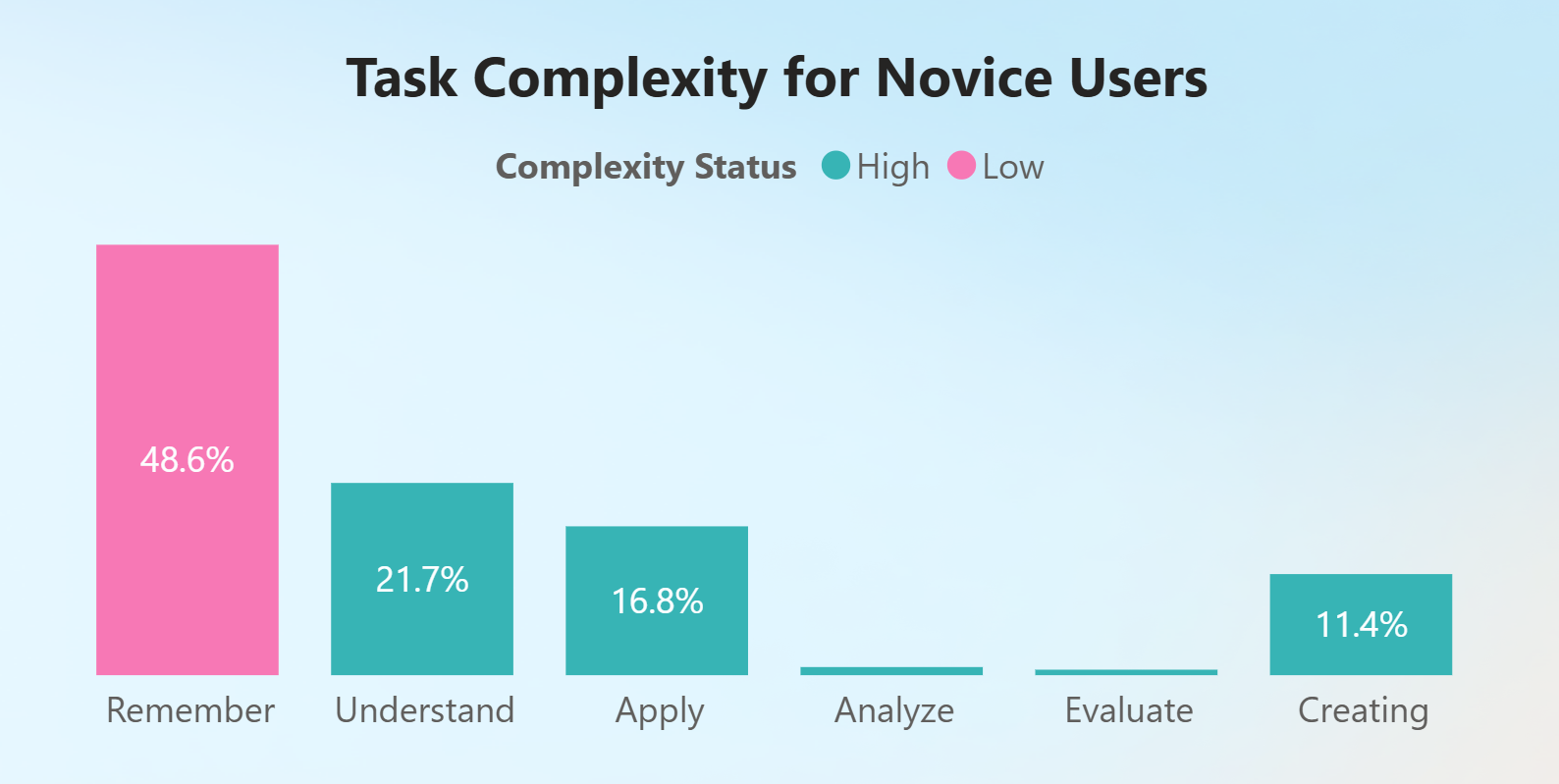
In contrast, novice users engaged more in professional tasks relating to business and finance and education and learning, mainly using the tool to recall information.
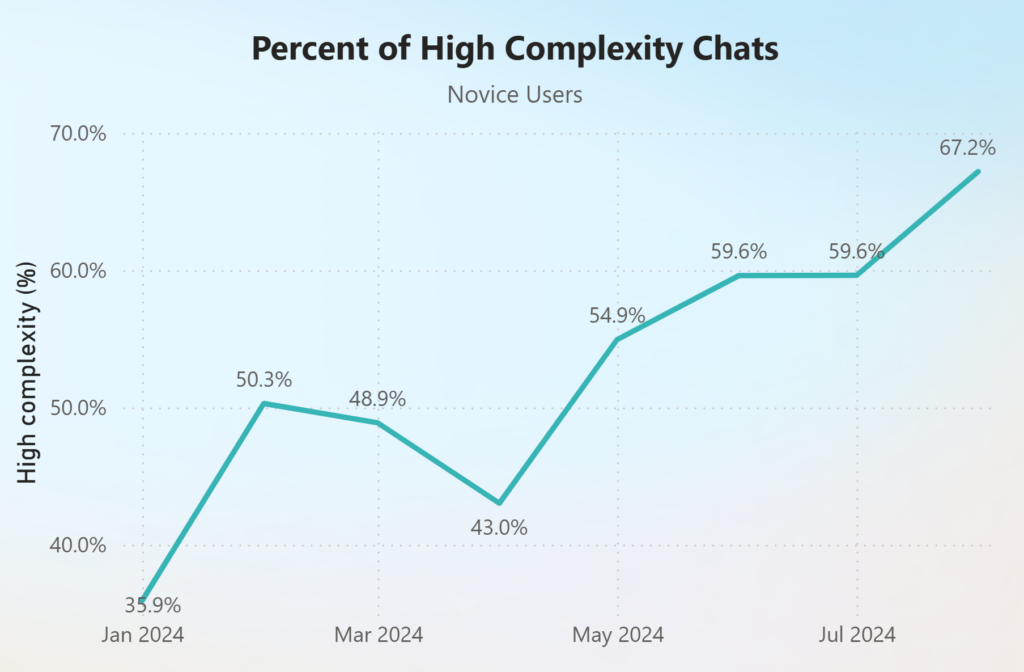
However, novices are targeting increasingly more complex tasks over time. Over the eight-month period, we see the percentage of high complexity tasks rise from about 36% to 67%, revealing that novices are learning and adapting quickly (see Figure 9).
How does user satisfaction vary according to expertise?
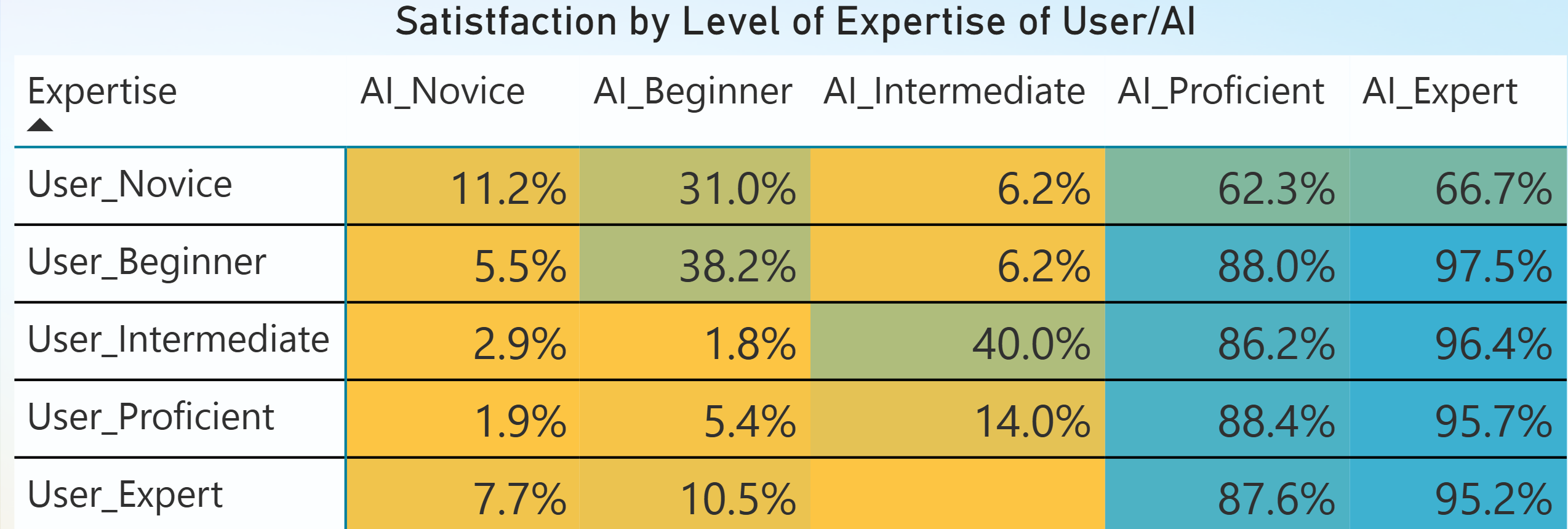
We classified both the user expertise and AI agent expertise for anonymous interactions in Copilot in Bing. We compared the level of user and AI agent expertise with our user satisfaction classifier.
The key takeaways are:
- Experts and proficient users are only satisfied with AI agents with similar expertise (expert/proficient).
- Novices are least satisfied, regardless of the expertise of the AI agent.
Conclusion
Understanding these metrics is vital for grasping user behavior over time and relating it to real-world business indicators. Users are finding value from complex professional knowledge work tasks, and novices are quickly adapting to the tool and finding these high value use-cases. By analyzing user satisfaction in conjunction with expertise levels, we can tailor our tools to better meet the needs of different user groups. Ultimately, these insights can help improve user understanding across a variety of tasks.
In our next post, we will examine the engineering processes involved in LLM-generated classification.




{kind=link}