


At a glance
- VLM-based robot planners struggle with long, complex tasks because natural-language plans can be ambiguous, especially when specifying both actions and locations.
- GroundedPlanBench evaluates whether models can plan actions and determine where they should occur across diverse, real-world robot scenarios.
- Video-to-Spatially Grounded Planning (V2GP) is a framework that converts robot demonstration videos into spatially grounded training data, enabling models to learn planning and grounding jointly.
- Grounded planning improves both task success and action accuracy, outperforming decoupled approaches in benchmark and real-world evaluations.
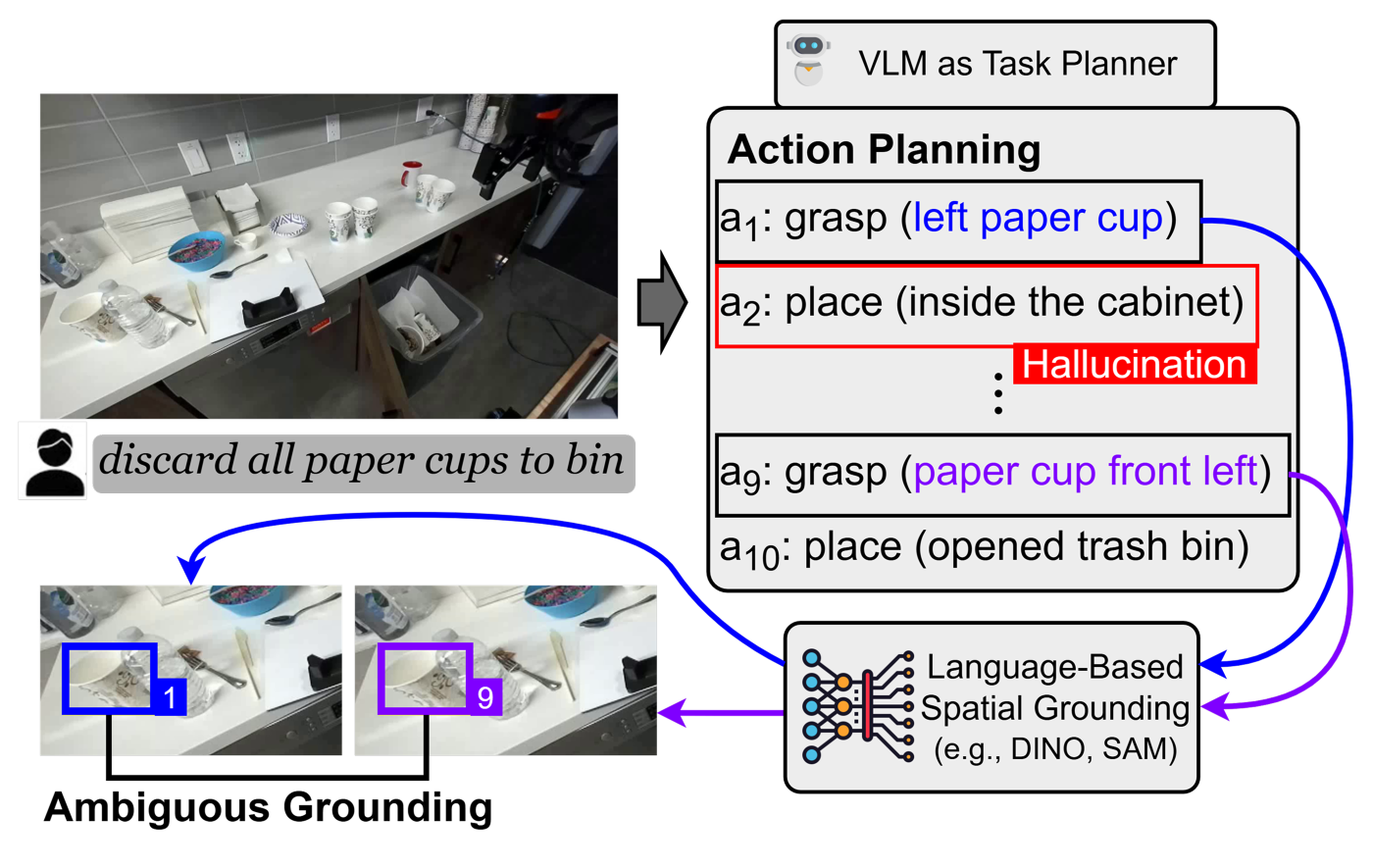
Vision-language models (VLMs) use images and text to plan robot actions, but they still struggle to decide what actions to take and where to take them. Most systems split these decisions into two steps: a VLM generates a plan in natural language, and a separate model translates it into executable actions. This approach often breaks down for long, complex tasks because natural-language plans can be ambiguous or even hallucinated when specifying actions and locations (Figure 1). Because planning and spatial reasoning are handled separately, errors in one stage can propagate to the next. This raises a key question: can a VLM determine both what to do and where to do it simultaneously?
Planning with spatial grounding
To address this problem, we developed GroundedPlanBench (opens in new tab). In our paper, “Spatially Grounded Long-Horizon Task Planning in the Wild,” we describe how this new benchmark evaluates whether VLMs can plan actions and determine where those actions should occur across diverse real-world environments. We also built Video-to-Spatially Grounded Planning (V2GP), a framework that converts robot demonstration videos into training data to help VLMs learn this capability.
Evaluating these with both open- and closed-source VLMs, we found that grounded planning for long, complex tasks is challenging. At the same time, V2GP improves both planning and grounding, with gains validated on our benchmark and in real-world experiments using robots.
How GroundedPlanBench works
To create realistic robot scenarios, we built our benchmark from 308 robot manipulation scenes in the Distributed Robot Interaction Dataset (DROID) (opens in new tab), a large collection of recordings of robots performing tasks. We worked with experts to review each scene and define tasks that a robot could perform. Each task was written in two styles: explicit instructions that clearly describe the actions (e.g., “put a spoon on the white plate”) and implicit instructions that describe the goal more generally (e.g., “tidy up the table”).
For each task, the plan was broken down into four basic actions—grasp, place, open, and close—each tied to a specific location in the image. Grasp, open, and close actions were linked to a box drawn around the target object, while place actions were linked to a box showing where the object should be placed.
Figure 2 illustrates medium- and long-duration tasks, along with their explicit and implicit instructions. In total, GroundedPlanBench contains 1,009 tasks, ranging from 1–4 actions (345 tasks) to 5–8 (381) and 9–26 (283).

How V2GP works
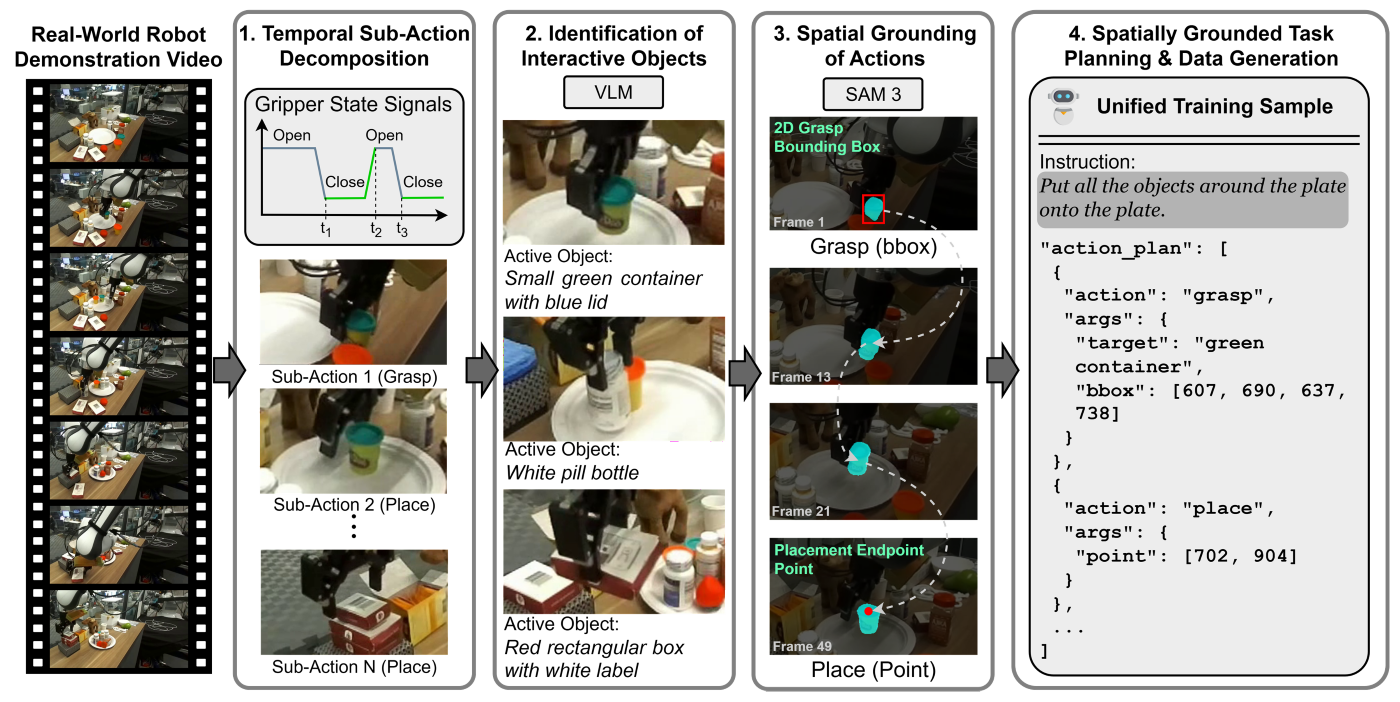
The V2GP framework first detects moments when the robot interacts with objects using the recorded gripper signals. It then generates a text description of the manipulated object with a multimodal language model. Guided by this description, the system tracks the object across the video using Meta’s advanced open-vocabulary image and video segmentation model, SAM3. The system then constructs grounded plans from the tracking results, identifying the object’s location at the moment it is grasped and where it is placed.
This process is illustrated in Figure 3. It yielded 43K grounded plans with varying lengths: 34,646 plans with 1–4 actions, 4,368 with 5–8 actions, and 4,448 with 9–26 actions.
Evaluating decoupled versus grounded planning
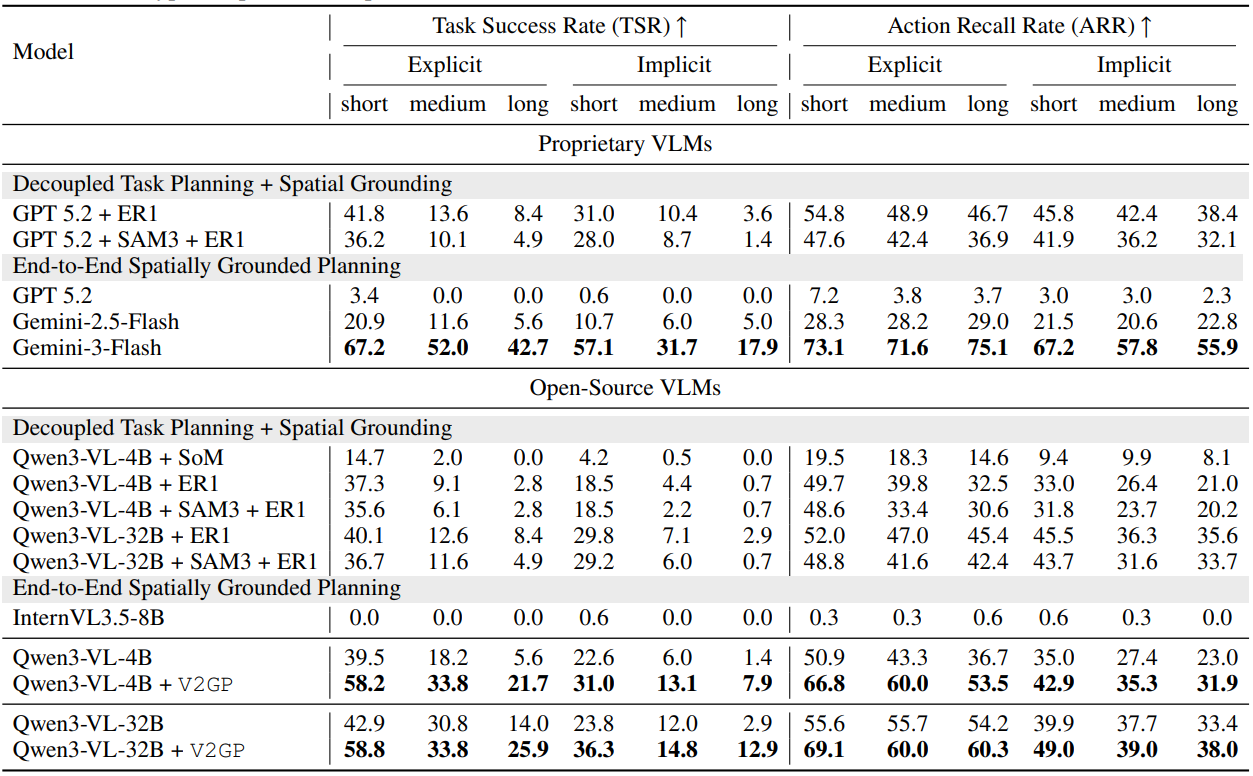
To evaluate GroundedPlanBench in real-world robotic settings, we used Qwen3-VL (opens in new tab) as our base model. Qwen3-VL is a vision-language model that processes text, images, and video to support multimodal reasoning. It performs well on standard multimodal reasoning benchmarks without additional training. We first evaluated it, along with other proprietary models, on GroundedPlanBench without any task-specific training (Table 1). We then fine-tuned it on V2GP training data and compared it with a decoupled approach, in which planning and grounding are handled separately.
In this setup, a VLM first generated a plan describing what the robot should do. We used GPT-5.2 or Qwen3-VL-4B for this step. The plan was then passed to a spatial grounding model, Embodied-R1 (opens in new tab), which converted the plans into executable signals. Embodied-R1 is a large vision-language model trained for embodied reasoning and pointing, where the model identifies specific locations in the image to guide the robot’s actions. We selected it for spatial grounding because its training targets embodied spatial reasoning and point-based localization, making it well suited for grounding model outputs to specific locations in an image.
Figure 4 highlights a key limitation of this approach: ambiguity in natural language. For example, Qwen3-VL-4B generated grasp actions by referring to “napkin on the table” for all four napkins in the scene, leading Embodied-R1 to ground each action the same napkin. GPT-5.2 produced more descriptive phrases, such as “top-left napkin” or “upper-center napkin,” but these were still too imprecise for the model to reliably distinguish between them and were again grounded to the same object.

This limitation becomes more pronounced in real-world robot manipulation, where environments are often cluttered and complex. As a result, decoupled approaches struggle to work reliably. In contrast, our approach, grounded planning, performs planning and grounding jointly within a single model and improves both planning and grounding performance.
Table 1 presents evaluation results for open- and closed-source VLMs on GroundedPlanBench. Multi-step planning and handling of implicit instructions were challenging for all models, while training Qwen3-VL-4B and Qwen3-VL-32B with V2GP led to significant improvements in grounded planning.
PODCAST SERIES
AI Testing and Evaluation: Learnings from Science and Industry
Discover how Microsoft is learning from other domains to advance evaluation and testing as a pillar of AI governance.
Implications and looking forward
Integrating planning and grounding within a single model offers a path to more reliable robot manipulation in real-world settings. Rather than relying on separate stages, this approach keeps decisions about what to do and where to act tightly coupled, but models still struggle with longer, multi-step tasks and implicit instructions. Models must reason over longer sequences of actions and maintain consistency across many steps and goals described indirectly, as in everyday language.
Looking ahead, a promising direction combines grounded planning with world models, which enable robots to predict the outcomes of actions before executing them. Together, these capabilities could allow robots to decide what to do, where to act, and what will happen next, bringing us closer to systems that can plan and act reliably in the real world.
Acknowledgements
This research was conducted in collaboration with Korea University, Microsoft Research, University of Wisconsin-Madison, and supported by the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant (No. RS-2025-25439490) funded by the Korea government (MSIT).



 Makes It the Hottest Destination Now!")
{kind=link}