

“How much will it cost to run our chatbot on Amazon Bedrock?” This is one of the most frequent questions we hear from customers exploring AI solutions. And it’s no wonder — calculating costs for AI applications can feel like navigating a complex maze of tokens, embeddings, and various pricing models. Whether you’re a solution architect, technical leader, or business decision-maker, understanding these costs is crucial for project planning and budgeting. In this post, we’ll look at Amazon Bedrock pricing through the lens of a practical, real-world example: building a customer service chatbot. We’ll break down the essential cost components, walk through capacity planning for a mid-sized call center implementation, and provide detailed pricing calculations across different foundation models. By the end of this post, you’ll have a clear framework for estimating your own Amazon Bedrock implementation costs and understanding the key factors that influence them.
For those that aren’t familiar, Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock provides a comprehensive toolkit for powering AI applications, including pre-trained large language models (LLMs), Retrieval Augmented Generation (RAG) capabilities, and seamless integration with existing knowledge bases. This powerful combination enables the creation of chatbots that can understand and respond to customer queries with high accuracy and contextual relevance.
Solution overview
For this example, our Amazon Bedrock chatbot will use a curated set of data sources and use Retrieval-Augmented Generation (RAG) to retrieve relevant information in real time. With RAG, our output from the chatbot will be enriched with contextual information from our data sources, giving our users a better customer experience. When understanding Amazon Bedrock pricing, it’s crucial to familiarize yourself with several key terms that significantly influence the expected cost. These components not only form the foundation of how your chatbot functions but also directly impact your pricing calculations. Let’s explore these key components. Key Components
- Data Sources – The documents, manuals, FAQs, and other information artifacts that form your chatbot’s knowledge base.
- Retrieval-Augmented Generation (RAG) – The process of optimizing the output of a large language model by referencing an authoritative knowledge base outside of its training data sources before generating a response. RAG extends the already powerful capabilities of LLMs to specific domains or an organization’s internal knowledge base, without the need to retrain the model. It is a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts.
- Tokens – A sequence of characters that a model can interpret or predict as a single unit of meaning. For example, with text models, a token could correspond not just to a word, but also to a part of a word with grammatical meaning (such as “-ed”), a punctuation mark (such as “?”), or a common phrase (such as “a lot”). Amazon Bedrock prices are based on the number of input and output tokens processed.
- Context Window – The maximum amount of text (measured in tokens) that an LLM can process in one request. This includes both the input text and additional context needed to generate a response. A larger context window allows the model to consider more information when generating responses, enabling more comprehensive and contextually appropriate outputs.
- Embeddings – Dense vector representations of text that capture semantic meaning. In a RAG system, embeddings are created for both knowledge base documents and user queries, enabling semantic similarity searches to retrieve the most relevant information from your knowledge base to augment the LLM’s responses.
- Vector Store: A vector store contains the embeddings for your data sources and acts as your knowledge base.
Embeddings Model: Embedding models are machine learning models that convert data (text, images, code, etc.) into fixed-size numerical vectors. These vectors capture the semantic meaning of the input in a format that can be used for similarity search, clustering, classification, recommendation systems, and retrieval-augmented generation (RAG). - Large Language Models (LLMs) – Models trained on vast volumes of data that use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences. Amazon Bedrock offers a diverse selection of these foundation models (FMs), each with different capabilities and specialized strengths.
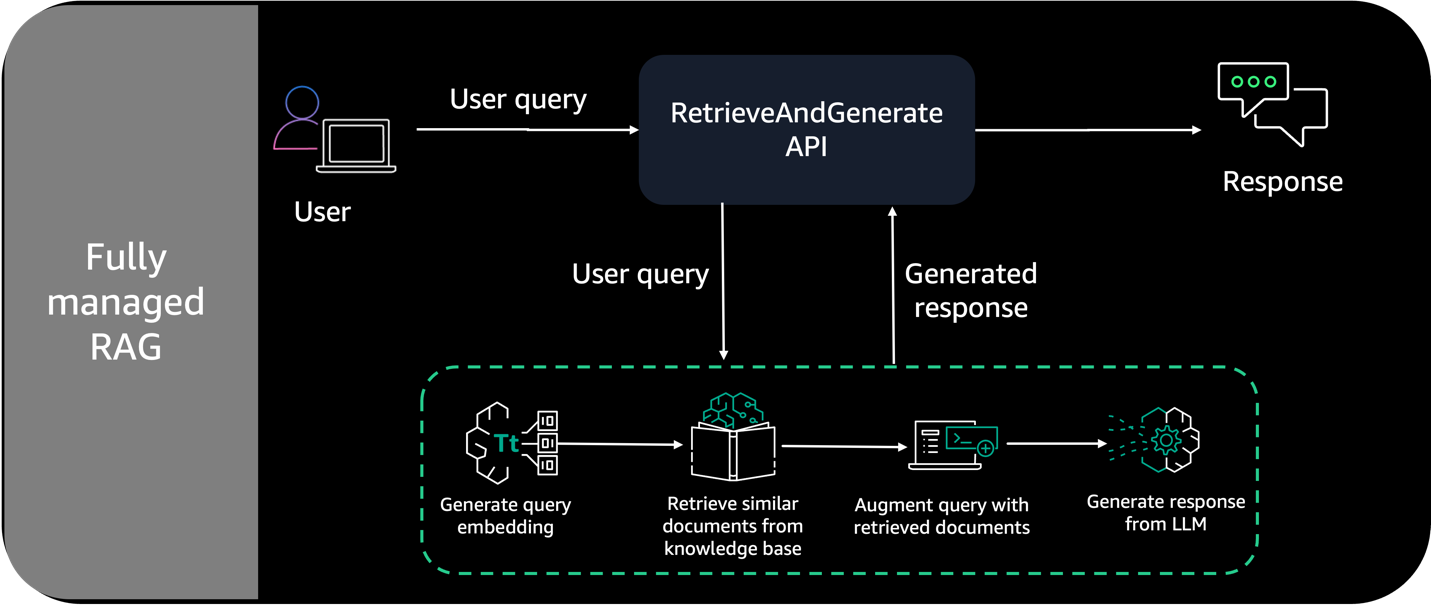
The figure below demonstrates the architecture of a fully managed RAG solution on AWS.
Estimating Pricing
One of the most challenging aspects of implementing an AI solution is accurately predicting your capacity needs. Without proper capacity estimation, you might either over-provision (leading to unnecessary costs) or under-provision (resulting in performance issues). Let’s walk through how to approach this crucial planning step for a real-world scenario. Before we dive into the numbers, let’s understand the key factors that affect your capacity and costs:
- Embeddings: Vector representations of your text that enable semantic search capabilities. Each document in your knowledge base needs to be converted into embeddings, which impacts both processing costs and storage requirements.
- User Queries: The incoming questions or requests from your users. Understanding your expected query volume and complexity is crucial, as each query consumes tokens and requires processing power.
- LLM Responses: The AI-generated answers to user queries. The length and complexity of these responses directly affect your token usage and processing costs.
- Concurrency: The number of simultaneous users your system needs to handle. Higher concurrency requirements may necessitate additional infrastructure and can affect your choice of pricing model.
To make this concrete, let’s examine a typical call center implementation. Imagine you’re planning to deploy a customer service chatbot for a mid-sized organization handling product inquiries and support requests. Here’s how we’d break down the capacity planning: First, consider your knowledge base. In our scenario, we’re working with 10,000 support documents, each averaging 500 tokens in length. These documents need to be chunked into smaller pieces for effective retrieval, with each document typically splitting into 5 chunks. This gives us a total of 5 million tokens for our knowledge base. For the embedding process, those 10,000 documents will generate approximately 50,000 embeddings when we account for chunking and overlapping content. This is important because embeddings affect both your initial setup costs and ongoing storage needs.
Now, let’s look at the operational requirements. Based on typical call center volumes, we’re planning for:
- 10,000 customer queries per month
- Query lengths varying from 50 to 200 tokens (depending on complexity)
- Average response length of 100 tokens per interaction
- Peak usage of 100 simultaneous users
When we aggregate these numbers, our monthly capacity requirements shape up to:
- 5 million tokens for processing our knowledge base
- 50,000 embeddings for semantic search
- 500,000 tokens for handling user queries
- 1 million tokens for generating responses
Understanding these numbers is crucial because they directly impact your costs in several ways:
- Initial setup costs for processing and embedding your knowledge base
- Ongoing storage costs for maintaining your vector database and document storage
- Monthly processing costs for handling user interactions
- Infrastructure costs to support your concurrency requirements
This gives us a solid foundation for our cost calculations, which we’ll explore in detail in the next section.
Calculating total cost of ownership (TCO)
Amazon Bedrock offers flexible pricing modes. With Amazon Bedrock, you are charged for model inference and customization. You have a choice of two pricing plans for inference: 1. On-Demand and Batch: This mode allows you to use FMs on a pay-as-you-go basis without having to make time-based term commitments. 2. Provisioned Throughput: This mode allows you to provision sufficient throughput to meet your application’s performance requirements in exchange for a time-based term commitment.
- On-demand – Ideal for infrequent or unpredictable usage
- Batch – Designed for processing large volumes of data in a single operation
- Provisioned throughput – Tailored for applications with consistent and predictable workloads
To calculate the TCO for this scenario as one-time cost we’ll consider the foundation model, the volume of data in the knowledge base, the estimated number of queries and responses, and the concurrency level mentioned above. For this scenario we’ll be using an on-demand pricing model and showing how the pricing would be for some of the foundation models available on Amazon Bedrock.
The On-Demand Pricing formula will be:
The cost of this setup will be the sum of cost of LLM inferences and cost of vector store. To estimate cost of inferences, you can obtain the number of input tokens, context size and output tokens in the response metadata returned by the LLM. Total Cost Incurred = ((Input Tokens + Context Size) * Price per 1000 Input Tokens + Output tokens * Price per 1000 Output Tokens) + Embeddings. For input tokens we will be adding an additional context size of about 150 tokens for User Queries. Therefore as per our assumption of 10,000 User Queries, the total Context Size will be 1,500,000 tokens.
The following is a comparison of estimated monthly costs for various models on Amazon Bedrock based on our example use case using the on-demand pricing formula:
Embeddings Cost:
For text embeddings on Amazon Bedrock, we can choose from Amazon Titan Embeddings V2 model or Cohere Embeddings Model. In this example we are calculating a one-time cost for the embeddings.
- Amazon Titan Text Embeddings V2:
- Price per 1,000 input tokens – $0.00002
- Cost of Embeddings – (Data Sources + User Queries) * Embeddings cost per 1000 tokens
- (5,000,000 +500,000) * 0.00002/1000 = $0.11
- Cohere Embeddings:
- Price per 1,000 input tokens – $0.0001
- Cost of Embeddings – (5,000,000+500,000) * 0.0001/1000 =$0.55
The usual cost of vector stores has 2 components: size of vector data + number of requests to the store. You can choose whether to let the Amazon Bedrock console set up a vector store in Amazon OpenSearch Serverless for you or to use one that you have created in a supported service and configured with the appropriate fields. If you’re using OpenSearch Serverless as part of your setup, you’ll need to consider its costs. Pricing details can be found here: OpenSearch Service Pricing .
Here using the On-Demand pricing formula, the overall cost is calculated using some foundation models (FMs) available on Amazon Bedrock and the Embeddings cost.
- Claude 4 Sonnet: ((500,000 +1,500,000) tokens/1000 * $0.003 + 1,000,000 tokens/1000* $0.015 = $21+0.11= $21.11
- Claude 3 Haiku: ((500,000 +1,500,000) tokens/1000 * $0.00025 + 1,000,000 tokens/1000* $0.00125 = $1.75+0.11= $1.86
• Amazon Nova:
- Amazon Nova Pro: ((500,000 +1,500,000) tokens/1000 * $0.0008 + 1,000,000 tokens/1000* $0.0032= $4.8+0.11= $4.91
- Amazon Nova Lite: ((500,000 +1,500,000) tokens/1000 * $0.00006 + 1,000,000 tokens/1000* $0.00024 = $0.36+0.11= $0.47
• Meta Llama:
- Llama 4 Maverick (17B): ((500,000 +1,500,000) tokens/1000 * $0.00024 + 1,000,000 tokens/1000* $0.00097= $1.45+0.11= $1.56
- Llama 3.3 Instruct (70B): ((500,000 +1,500,000) tokens/1000 * $0.00072 + 1,000,000 tokens/1000* $0.00072 = $2.16+0.11= $2.27
Evaluate models not just on their natural language understanding (NLU) and generation (NLG) capabilities, but also on their price-per-token ratios for both input and output processing. Consider whether premium models with higher per-token costs deliver proportional value for your specific use case, or if more cost-effective alternatives like Amazon Nova Lite or Meta Llama models can meet your performance requirements at a fraction of the cost.
Conclusion
Understanding and estimating Amazon Bedrock costs doesn’t have to be overwhelming. As we’ve demonstrated through our customer service chatbot example, breaking down the pricing into its core components – token usage, embeddings, and model selection – makes it manageable and predictable.
Key takeaways for planning your Bedrock implementation costs:
- Start with a clear assessment of your knowledge base size and expected query volume
- Consider both one-time costs (initial embeddings) and ongoing operational costs
- Compare different foundation models based on both performance and pricing
- Factor in your concurrency requirements when choosing between on-demand, batch, or provisioned throughput pricing
By following this systematic approach to cost estimation, you can confidently plan your Amazon Bedrock implementation and choose the most cost-effective configuration for your specific use case. Remember that the cheapest option isn’t always the best – consider the balance between cost, performance, and your specific requirements when making your final decision.
Getting Started with Amazon Bedrock
With Amazon Bedrock, you have the flexibility to choose the most suitable model and pricing structure for your use case. We encourage you to explore the AWS Pricing Calculator for more detailed cost estimates based on your specific requirements.
To learn more about building and optimizing chatbots with Amazon Bedrock, check out the workshop Building with Amazon Bedrock.
We’d love to hear about your experiences building chatbots with Amazon Bedrock. Share your success stories or challenges in the comments!
About the authors
 Srividhya Pallay is a Solutions Architect II at Amazon Web Services (AWS) based in Seattle, where she supports small and medium-sized businesses (SMBs) and specializes in Generative Artificial Intelligence and Games. Srividhya holds a Bachelor’s degree in Computational Data Science from Michigan State University College of Engineering, with a minor in Computer Science and Entrepreneurship. She holds 6 AWS Certifications.
Srividhya Pallay is a Solutions Architect II at Amazon Web Services (AWS) based in Seattle, where she supports small and medium-sized businesses (SMBs) and specializes in Generative Artificial Intelligence and Games. Srividhya holds a Bachelor’s degree in Computational Data Science from Michigan State University College of Engineering, with a minor in Computer Science and Entrepreneurship. She holds 6 AWS Certifications.
 Prerna Mishra is a Solutions Architect at Amazon Web Services(AWS) supporting Enterprise ISV customers. She specializes in Generative AI and MLOPs as part of Machine Learning and Artificial Intelligence community. She graduated from New York University in 2022 with a Master’s degree in Data Science and Information Systems.
Prerna Mishra is a Solutions Architect at Amazon Web Services(AWS) supporting Enterprise ISV customers. She specializes in Generative AI and MLOPs as part of Machine Learning and Artificial Intelligence community. She graduated from New York University in 2022 with a Master’s degree in Data Science and Information Systems.
 Brian Clark is a Solutions Architect at Amazon Web Services (AWS) supporting Enterprise customers in the financial services vertical. He is a part of the Machine Learning and Artificial Intelligence community and specializes in Generative AI and Agentic workflows. Brian has over 14 years of experience working in technology and holds 8 AWS certifications.
Brian Clark is a Solutions Architect at Amazon Web Services (AWS) supporting Enterprise customers in the financial services vertical. He is a part of the Machine Learning and Artificial Intelligence community and specializes in Generative AI and Agentic workflows. Brian has over 14 years of experience working in technology and holds 8 AWS certifications.




{kind=link}